NVIDIA Launches Tesla K40
by Ryan Smith on November 18, 2013 9:00 AM EST
Kicking off today is the annual International Conference for High Performance Computing, Networking, Storage, and Analysis, better known as SC. For NVIDIA, next to their annual GPU Technology Conference, SC is their second biggest GPU compute conference, and is typically the venue for NVIDIA’s summer/fall announcements. And with a number of announcements in stow NVIDIA has split up their major announcements over two weeks. Last week we saw CUDA 6, which introduced unified memory support for compute workloads for NVIDIA’s products, and today we’ll be seeing a couple of other things, starting with Tesla K40.
With both the GeForce and Quadro lineups getting the full GK110 treatment in the last couple of months with GeForce GTX 780 Ti and Quadro K6000 respectively, it was only a matter of time until NVIDIA gave the Tesla lineup the same treatment. Tesla K20(X) was of course the first product to launch with NVIDIA’s flagship GK110 GPU, and now with K40 the Tesla lineup will become the final product line to be upgraded to full GK110 specifcations.
| NVIDIA Tesla Family Specification Comparison | ||||||
| Tesla K40 | Tesla K20X | Tesla K20 | Tesla M2090 | |||
| Stream Processors | 2880 | 2688 | 2496 | 512 | ||
| Core Clock | 745MHz | 732MHz | 706MHz | 650MHz | ||
| Boost Clock(s) | 810MHz, 875MHz | N/A | N/A | N/A | ||
| Shader Clock | N/A | N/A | N/A | 1300MHz | ||
| Memory Clock | 6GHz GDDR5 | 5.2GHz GDDR5 | 5.2GHz GDDR5 | 3.7GHz GDDR5 | ||
| Memory Bus Width | 384-bit | 384-bit | 320-bit | 384-bit | ||
| VRAM | 12GB | 6GB | 5GB | 6GB | ||
| Single Precision | 4.29 TFLOPS | 3.95 TFLOPS | 3.52 TFLOPS | 1.33 TFLOPS | ||
| Double Precision | 1.43 TFLOPS (1/3) | 1.31 TFLOPS (1/3) | 1.17 TFLOPS (1/3) | 655 GFLOPS (1/2) | ||
| Transistor Count | 7.1B | 7.1B | 7.1B | 3B | ||
| TDP | 235W | 235W | 225W | 250W | ||
| Cooling | Active/Passive | Passive | Active/Passive | N/A | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | TSMC 40nm | ||
| Architecture | Kepler | Kepler | Kepler | Fermi | ||
| Launch Price | $5499? | ~$3799 | ~$3299 | N/A | ||
Like the other fully enabled GK110 cards we’ve seen, Tesla K40 is a moderate spec bump that sees NVIDIA enabling the 15th and final SMX already present on GK110, while also giving the GPU and memory clockspeeds a bump. Compared to the K20X, the K40 gets a very slight GPU clockspeed increase from 732MHz to 745Mhz (2%), which coupled with the additional SMX gives it around 9% more compute throughput on paper. This will bring it to a total of 4.29TFLOPS single precision, or 1.43TFLOPS double precision. Meanwhile for memory performance the memory clockspeed has seen a more significant bump, going from 5.2GHz to a full 6GHz (15% more), or in terms of raw bandwidth from 250GB/sec to 288GB/sec.
Perhaps more significantly however, with K40 the Tesla family finally gets access to 4Gbit GDDR5 modules, which have only recently reached mass production. With Tesla K20X previously topping out at 6GB (24 x 2Gbit), NVIDIA is taking K40 to 12GB (24 x 4Gbit), making it the first Tesla card with that much memory. Like Quadro K6000, which is also launching with 12GB of VRAM, NVIDIA has a number of customers in the compute market who are bottlenecked at either the algorithmic or data set levels by memory capacity. So the additional capacity should offer a welcome improvement for those users, and unlock at least a few more workloads that couldn’t properly fit inside of 6GB.

As for power and cooling, the requirements there will not be changing. K40 needs to be drop-in compatible with K20X, so the TDP remains at 235W; NVIDIA reaping the benefits of binning and the new B1 stepping of GK110, but not having the headroom for a significant GPU clockspeed increase. Taking a step beyond K20X however, K40 will be offered in both passive and active cooling configurations – K20X was only offered in passive – so unlike K20X, K40 can be dropped in a wider array of systems than just rackmount servers and other devices with dedicated expansion slot cooling.
But with that said, despite the fact that K40 is just an iteration on K20 and a member of the Kepler Tesla family (as opposed to being a new product line of its own), K40 does come with one new trick that the K20 cards did not: GPU Boost. To be clear here this isn’t the same GPU Boost we saw in NVIDIA’s Kepler GeForce cards – for one thing it’s not automatic – but it is similar. Since these cards are both TDP limited and all of the cards in a cluster need to operate at the same clockspeed to maintain synchronization, NVIDIA cannot ship K40 at a higher clockspeed than it’s going to be able to sustain. However that doesn’t mean the GK110 GPU underlying K40 can’t clock higher (we’ve seen it in GTX 780 Ti) so NVIDIA has split the difference and will be offering selectable clockspeeds under the GPU Boost moniker.
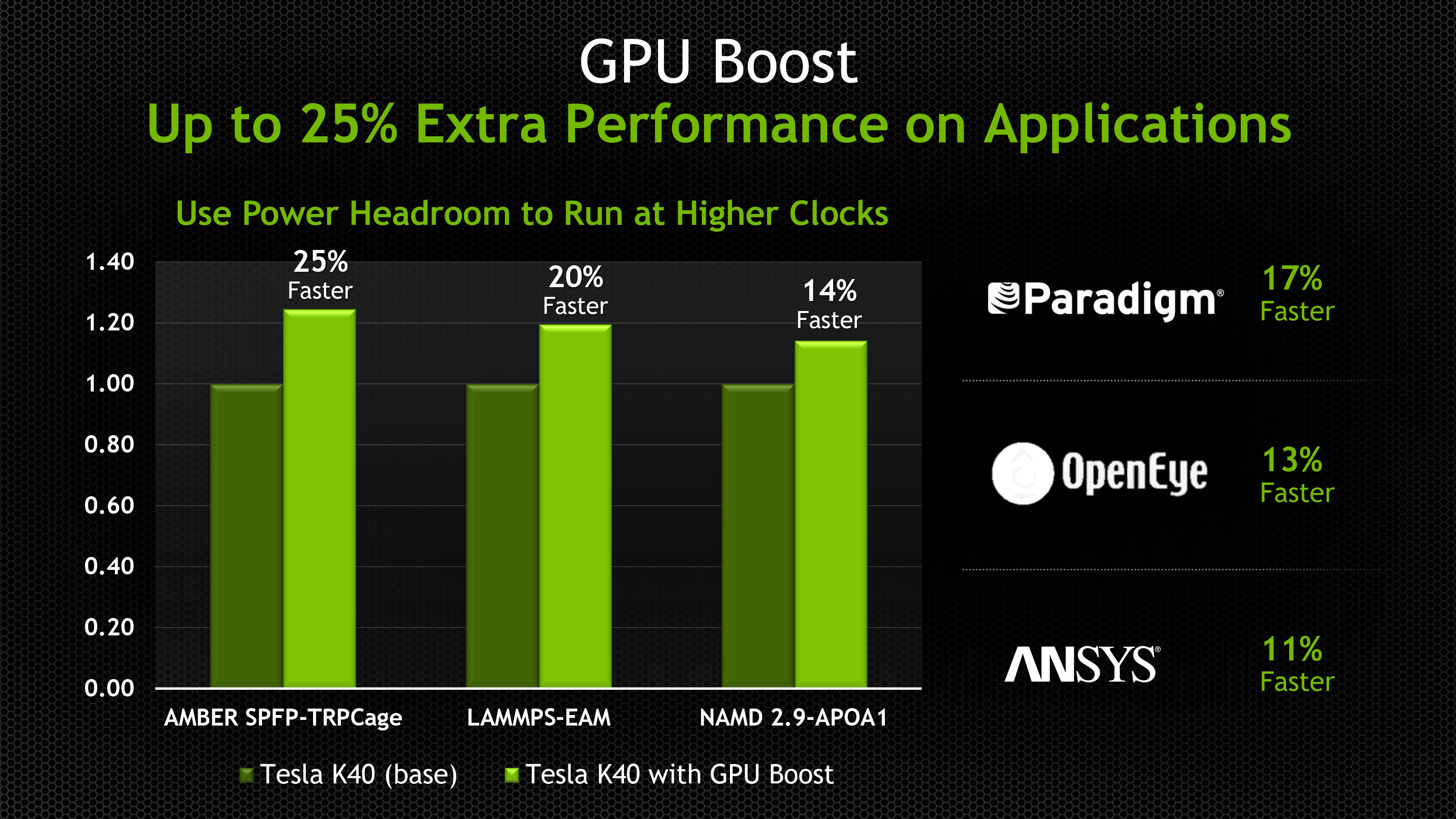
Besides the 745MHz default clockspeed, K40 cards will also be able to be set at 810MHz and 875MHz, significant clockspeed bumps that would have equally significant performance impacts. These higher clockspeeds are operator selected, and are primarily intended to be used in systems where the workload wasn’t maxing out K40’s 235W TDP in the first place, giving operators the ability to squeeze out a bit more performance by bringing K40 closer to its TDP limits. These higher clockspeeds don’t change the TDP limit itself, and in all likelihood come with very significant power consumption increases (due to the squared impact of voltage), so it will be up to operators to profile their workloads and select a suitable clockspeed, least they cause their cards to throttle and potentially lose sync. Ultimately in cases where these higher clockspeeds can be used, the 17% clockspeed increase from using 875MHz would compound with K40’s earlier 9% performance increase over K20X and put K40 at upwards of 28% faster than K20X.
On a further note, there is one last feature upgrade that is new for K40. For K20(X) NVIDIA limited those cards to PCI Express 2.0 speeds, despite the fact that the underlying hardware was designed to support PCI Express 3.0. For K40 however NVIDIA is finally enabling full PCI Express 3.0 speeds, which would coincide the launch of Intel’s Ivy Bridge-E hardware and the fixed compatibility between the two platforms. For the relevant systems this offers to double the available bandwidth between individual Tesla cards and between cards and the host CPUs – going from 8GB/sec to 15.75GB/sec – something that relative to the high-speed local memory was at times a massive bottleneck for these cards.

Wrapping things up, K40 will be a hard launch from NVIDIA and their partners, with individual cards and OEM systems equipped with them expected to be available today. We’re already seeing some individual cards on sale a few hours before the official launch, placing them at $5,500, though it should be noted that these are retail prices and NVIDIA does not have public MSRPs for Tesla cards.








9 Comments
View All Comments
Acarney - Monday, November 18, 2013 - link
I'm a little confused by the passive cooling of these cards. What are dedicated expansion slot cooling solutions like? Does that just mean a well ventilated system? I'm very curious why these cards can ship with a passive option but none of the home desktop cards can ship with a passive option. I'm been looking for ages for a solution that can handle most games at "high" settings (or maybe some slightly older games at "max") and 1080p res for building a HTPC/Console replacement but I want to keep it pretty much passive or just one very low dB system fan and nothing seems to exist out there for keeping the video card cool... (HD-Plex has the CPU covered for a passive solution...)Ryan Smith - Tuesday, November 19, 2013 - link
The passive cards are meant for rackmount servers, which will have strong fans in the sever specifically meant to cool the expansion slots. A standard PC case, even with good airflow, would not work with these cards. You need high volume, highly directed (and high noise) airflow for this to work.HollyDOL - Tuesday, November 19, 2013 - link
Yep... Imagine circular saw running on max with no load (similar sound). The one for which you need ear protection when you work nearby. Oh, and that "saw" spins at 15k rpm...mehminer - Saturday, March 6, 2021 - link
I know I"m a bit late, but maybe someone will see this. There are online vendors of cooling kits for K40 (and other Nvidia) cards. Here's one: poly-fab , https://www.ebay.com/itm/Nvidia-Tesla-Compact-Blow...Communism - Tuesday, November 19, 2013 - link
Something like thishttp://images.anandtech.com/doci/6842/20130319_103...
From this article:
http://www.anandtech.com/show/6842/
fteoath64 - Wednesday, November 20, 2013 - link
"passive cooling of these cards¨ ?!!. Take a look at the vents on the front side of the cards. These are exhaust vents for the twin large fans inside the unit!. There is no way a 200+ watt chip is going to be passively cooled in such a small enclosure!. The amount of air being pushed is significant just to keep the card under 70 deg C. This in a machine room of 16 DegC controlled temp, you can see the temp delta, hence the heat dissipated by each of these cards.comomolo - Tuesday, November 19, 2013 - link
I hope we can see a comparison between this and the newest AMD S10000, which also comes with 12GB of memory, some 30% more TFLOPS in single precision mode and an (expected from extrapolation from the 6GB version) significantly lower price.woogitboogity - Thursday, March 27, 2014 - link
I don't think AMD should be seen as a serious contender in this area. The closest thing they had was their "Close to Metal" initiative which, true to its name, offered a great deal of control but was as useless in the long run as something programmed completely in assembly: architecture and the software/hardware ecosystem are what make all the difference. Theoretical FLOPS by itself (in single precision to boot) means about as much theoretical 1000 Base-T networking did when the standard was created in 1998... practically nothing. Maybe you might actually use the bandwidth for a highly customized application but without any abstraction all you have is a very specific solution that cannot be generalized to anything else.benouz - Thursday, November 27, 2014 - link
Do you know OpenCL?The common API designed for parallel computing. This is what AMD and many others HW vendor support
https://www.khronos.org/opencl/