NVIDIA: Grace Hopper Has Entered Full Production & Announcing DGX GH200 AI Supercomputer
by Ryan Smith on May 29, 2023 7:00 AM EST- Posted in
- GPUs
- CPUs
- NVIDIA
- Machine Learning
- HBM3
- DGX
- NVLink
- Grace
- H100
- Grace Hopper

Teeing off an AI-heavy slate of announcements for NVIDIA, the company has confirmed that their Grace Hopper “superchip” has entered full production. The combination of a Grace CPU and Hopper H100 GPU, Grace Hopper is designed to be NVIDIA’s answer for customers who need a more tightly integrated CPU + GPU solution for their workloads – particularly for AI models.
In the works for a few years now, Grace Hopper is NVIDIA’s efforts to leverage both their existing strength in the GPU space and newfound efforts in the CPU space to deliver a semi-integrated CPU/GPU product unlike anything their top-line competitors offer. With NVIDIA’s traditional dominance in the GPU space, the company has essentially been working backwards, combining their GPU technology with other types of processors (CPUs, DPUs, etc) in order to access markets that benefit from GPU acceleration, but where fully discrete GPUs may not be the best solution.
| NVIDIA Grace Hopper Specifications | |||
| Grace Hopper (GH200) | |||
| CPU Cores | 72 | ||
| CPU Architecture | Arm Neoverse V2 | ||
| CPU Memory Capacity | <=480GB LPDDR5X (ECC) | ||
| CPU Memory Bandwidth | <=512GB/sec | ||
| GPU SMs | 132 | ||
| GPU Tensor Cores | 528 | ||
| GPU Architecture | Hopper | ||
| GPU Memory Capcity | <=96GB | ||
| GPU Memory Bandwidth | <=4TB/sec | ||
| GPU-to-CPU Interface | 900GB/sec NVLink 4 |
||
| TDP | 450W - 1000W | ||
| Manufacturing Process | TSMC 4N | ||
| Interface | Superchip | ||
In this first NVIDIA HPC CPU + GPU mash-up, the Hopper GPU is the known side of the equation. While it only started shipping in appreciable volumes this year, NVIDIA was detailing the Hopper architecture and performance expectations over a year ago. Based on the 80B transistor GH100 GPU, H100 brings just shy of 1 PFLOPS of FP16 matrix math throughput for AI workloads, as well as 80GB of HBM3 memory. H100 is itself already a huge success – thanks to the explosion of ChatGPT and other generative AI services, NVIDIA is already selling everything they can make – but NVIDIA is still pushing ahead with their efforts to break into markets where the workloads require closer CPU/GPU integration.

Being paired with H100, in turn, is NVIDIA’s Grace CPU, which itself just entered full production a couple of months ago. The Arm Neoverse V2-based chip packs 72 CPU cores, and comes with up to 480GB of LPDDR5X memory. And while the CPU cores are themselves plenty interesting, the bigger twist with Grace has been NVIDIA’s decision to co-package the CPU with LPDDR5X, rather than using slotted DIMMs. The on-package memory has allowed NVIDIA to use both higher clocked and lower power memory – at the cost of expandability – which makes Grace unlike any other HPC-class CPU on the market. And potentially a very big deal for Large Language Model (LLM) training, given the emphasis on both dataset sizes and the memory bandwidth needed to shuffle that data around.
It’s that data shuffling, in turn, that helps to define a single Grace Hopper board as something more than just a CPU and GPU glued together on the same board. Because NVIDIA equipped Grace with NVLink support – NVIDIA’s proprietary high-bandwidth chip interconnect – Grace and Hopper have a much faster interconnect than a traditional, PCIe-based CPU + GPU setup. The resulting NVLink Chip-to-Chip (C2C) link offers 900GB/second of bandwidth between the two chips (450GB/sec in each direction), giving Hopper the ability to talk back to Grace even faster than Grace can read or write to its own memory.
The resulting board, which NVIDIA calls their GH200 “superchip”, is meant to be NVIDIA’s answer to the AI and HPC markets for the next product cycle. For customers who need a more local CPU than a traditional CPU + GPU setup – or perhaps more pointedly, more quasi-local memory than a stand-alone GPU can be equipped with – Grace Hopper is NVIDIA’s most comprehensive compute product yet. Meanwhile, with there being some uncertainty over just how prevalent the Grace-only (CPU-only) superchip will be, given that NVIDIA is currently on an AI bender, Grace Hopper may very well end up being where we see the most of Grace, as well.
According to NVIDIA, systems incorporating GH200 chips are slated to be available later this year.
DGX GH200 AI Supercomputer: Grace Hopper Goes Straight To the Big Leagues
Meanwhile, even though Grace Hopper is not technically out the door yet, NVIDIA is already at work building its first DGX system around the chip. Though in this case, “DGX” may be a bit of a misnomer for the system, which unlike other DGX systems isn’t a single node, but rather a full-on multi-rack computational cluster – hence NVIDIA terming it a “supercomputer.”
At a high level, the DGX GH200 AI Supercomputer is a complete, turn-key, 256 node GH200 cluster. Spanning some 24 racks, a single DGX GH200 contains 256 GH200 chips – and thus, 256 Grace CPUs and 256 H100 GPUs – as well as all of the networking hardware needed to interlink the systems for operation. In cumulative total, a DGX GH200 cluster offers 120TB of CPU-attached memory, another 24TB of GPU-attached memory, and a total of 1 EFLOPS of FP8 throughput (with sparsity).

Look Closer: That's Not a Server Node - That's 24 Server Racks
Linking the nodes together is a two-layer networking system built around NVLink. 96 local, L1 switches provide immediate communications between the GH200 blades, while another 36 L2 switches provide a second layer of connectivity tying together the L1 switches. And if that’s not enough scalability for you, DGX GH200 clusters can be further scaled up in size by using InfiniBand, which is present in the cluster as part of NVIDIA’s use of ConnectX-7 network adapters.
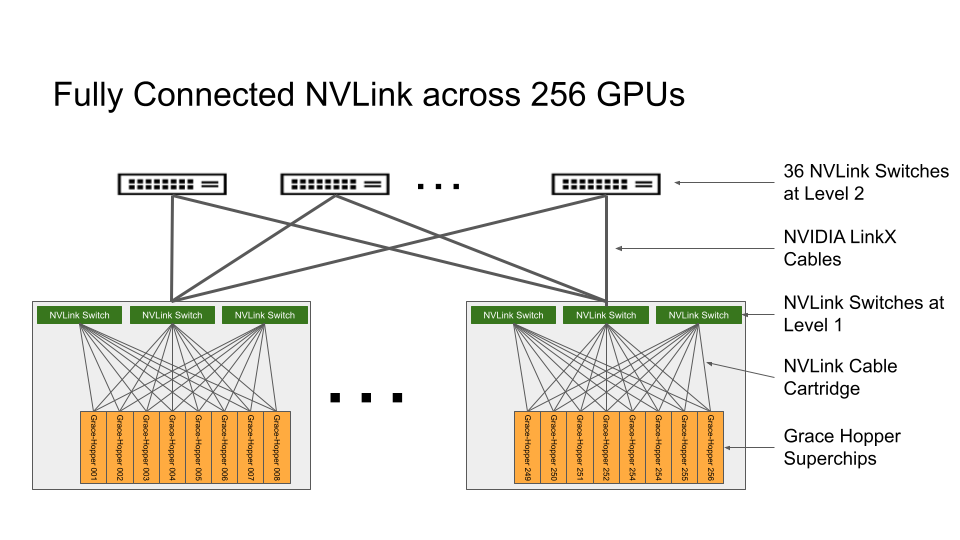
The target market for the sizable silicon cluster is training large AI models. NVIDIA is leaning heavily on their existing hardware and toolsets in the field, combined with the sheer amount of memory and memory bandwidth a 256-node cluster affords to be able to accommodate some of the largest AI models around. The recent explosion in interest in large language models has exposed just how much memory capacity is a constraining factor, so this is NVIDIA’s attempt to offer a single-vendor, integrated solution for customers with especially large models.
And while not explicitly disclosed by NVIDIA, in a sign that they all pulling out all of the stops for the DGX GH200 cluster, the memory capacities they’ve listed indicate that NVIDIA isn’t just shipping regular H100 GPUs as part of the system, but rather they are using their limited availability 96GB models, which have the normally-disabled 6th stack of HBM3 memory enabled. So far, NVIDIA only offers these H100 variants in a handful of products – the specialty H100 NVL PCIe card and now in some GH200 configurations – so DGX GH200 is slated to get some of NVIDIA’s best silicon.
Of course, don’t expect a supercomputer from NVIDIA to come cheaply. While NVIDIA is not announcing any pricing this far in advance, based on HGX H100 board pricing (8x H100s on a carrier board for $200K), a single DGX GH200 is easily going to cost somewhere in the low 8 digits. Suffice it to say, DGX GH200 is aimed at a rather specific subset of Enterprise clientele – those who need to do a lot of large model training and have the deep pocketbooks to pay for a complete, turn-key solution.
Ultimately, however, DGX GH200 isn’t just meant to be a high-end system for NVIDIA to sell to deep-pocketed customers, but it’s the blueprint for helping their hyperscaler customers build their own GH200-based clusters. Building such a system is, after all, the best way to demonstrate how it works and how well it works, so NVIDIA is forging their own path in this regard. And while NVIDIA would no doubt be happy to sell a whole lot of these DGX systems directly, so long as it gets hyperscalers, CSPs, and others adopting GH200 in large numbers (and not, say, rival products), then that’s still going to be a win in NVIDIA’s books.
In the meantime, for the handful of businesses that can afford a DGX GH200 AI Supercomputer, according to NVIDIA the systems will be available by the end of the year.
Source: NVIDIA








8 Comments
View All Comments
Threska - Monday, May 29, 2023 - link
Does each one come with a nanosecond bundle?https://americanhistory.si.edu/collections/search/...
Dante Verizon - Monday, May 29, 2023 - link
More ARM toys. Nice.Bulat Ziganshin - Monday, May 29, 2023 - link
correction: 1000 tflops is 1 pflop, not 1 exaflop (which is 1000 pflops)lemurbutton - Tuesday, May 30, 2023 - link
Nvidia buying ARM would have led to some very interesting products and a 3rd competitor to AMD and Intel in SoCs in the PC/HPC space.lazarpandar - Tuesday, May 30, 2023 - link
They can still compete there without owning ARM outright....hix - Monday, June 5, 2023 - link
well to compete in cpu battle u need to know how to make one ,nvidia deff cantbrucethemoose - Tuesday, May 30, 2023 - link
Nvidia's bet on transformers acceleration was a good one. They had to make that commitment in silicon well before transformers became the monster it is today.But I bet they are kicking themselves over the 6xHBM VRAM limits, just like everyone else in the AI space.
CoreLogicCom - Tuesday, May 30, 2023 - link
How long until this chip shows up in a Cyberdyne Systems Model 101?