NVIDIA: H100 Hopper Accelerator Now in Full Production, DGX Shipping In Q1’23
by Ryan Smith on September 20, 2022 12:18 PM EST
With NVIDIA’s fall GTC event in full swing, the company touched upon the bulk of its core business in one way or another in this morning’s keynote. On the enterprise side of matters, one of the longest-awaited updates was the shipment status of NVIDIA’s H100 “Hopper” accelerator, which at introduction was slated to land in Q3 of this year. As it turns out, with Q3 already nearly over H100 is not going to make its Q3 availability date. But, according to NVIDIA the accelerator is in full production, and the first systems will be shipping from OEMs in October.
First revealed back in March at NVIDIA’s annual spring GTC event, the H100 is NVIDIA’s next-generation high performance accelerator for servers, hyperscalers, and similar markets. Based on the Hopper architecture and built on TSMC’s 4nm “4N” process, H100 is the follow-up to NVIDIA’s very successful A100 accelerator. Among other changes, the newest accelerator from the company implements HBM3 memory, support for transformer models within its tensor cores, support for dynamic programming, an updated version of multi-instance GPU with more robust isolation, and a whole lot more computational throughput for both vector and tensor datatypes. Based around NVIDIA’s hefty 80 billion transistor GH100 GPU, the H100 accelerator is also pushing the envelope in terms of power consumption, with a maximum TDP of 700 Watts.
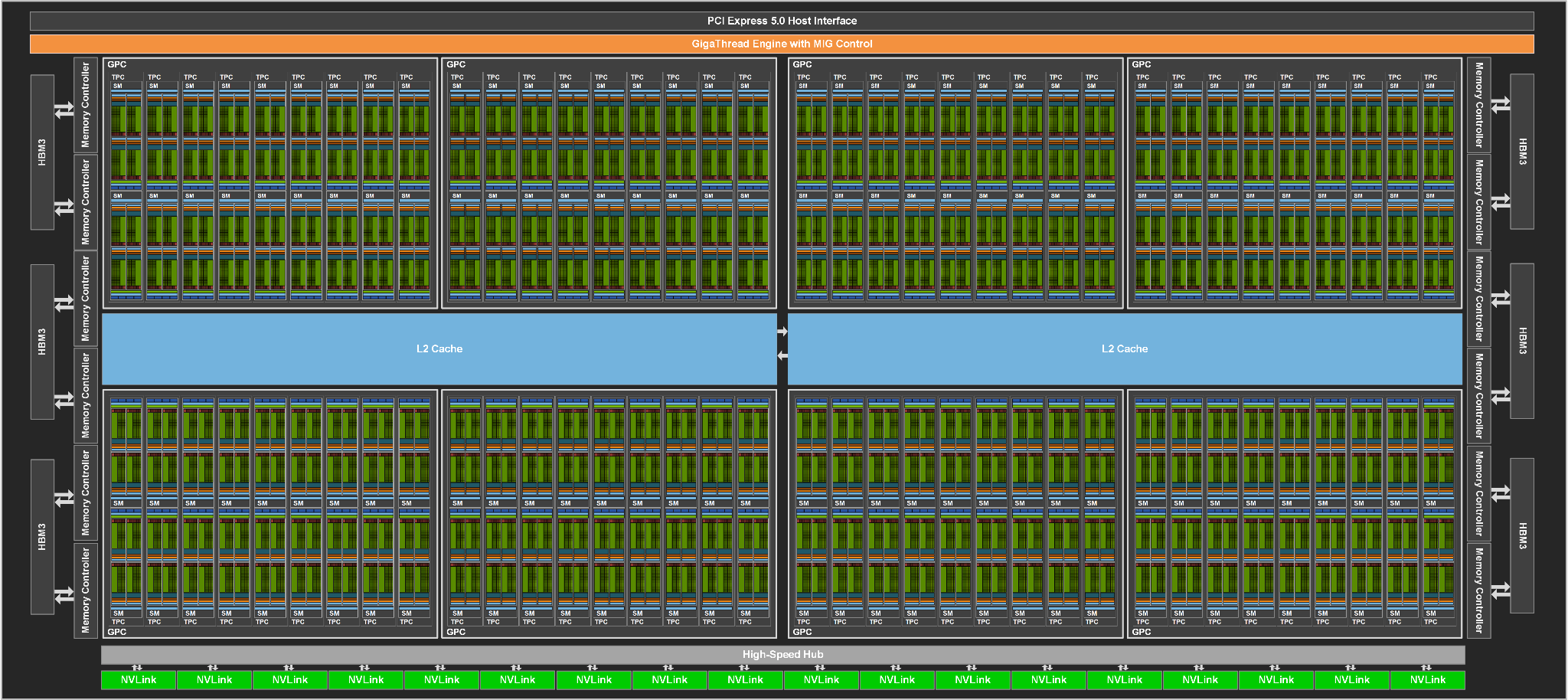
Given that NVIDIA’s spring GTC event didn’t precisely align with their manufacturing window for this generation, the H100 announcement earlier this year stated that NVIDIA would be shipping the first H100 systems in Q3. However, NVIDIA’s updated delivery goals outlined today mean that the Q3 date has slipped. The good news is that H100 is in “full production”, as NVIDIA terms it. The bad news is that it would seem that production and integration didn’t start quite on time; at this point the company does not expect the first production systems to reach customers until October, the start of Q4.
Throwing a further spanner into matters, the order in which systems and products are rolling out is essentially being reversed from NVIDIA’s usual strategy. Rather than starting with systems based on their highest-performance SXM form factor parts first, NVIDIA’s partners are instead starting with the lower performing PCIe cards. That is to say that the first systems shipping in October will be using the PCIe cards, and it will only be later in the year that NVIDIA’s partners ship systems that integrate the faster SXM cards and their HGX carrier board.
| NVIDIA Accelerator Specification Comparison | ||||||
| H100 SXM | H100 PCIe | A100 SXM | A100 PCIe | |||
| FP32 CUDA Cores | 16896 | 14592 | 6912 | 6912 | ||
| Tensor Cores | 528 | 456 | 432 | 432 | ||
| Boost Clock | ~1.78GHz (Not Finalized) |
~1.64GHz (Not Finalized) |
1.41GHz | 1.41GHz | ||
| Memory Clock | 4.8Gbps HBM3 | 3.2Gbps HBM2e | 3.2Gbps HBM2e | 3.0Gbps HBM2e | ||
| Memory Bus Width | 5120-bit | 5120-bit | 5120-bit | 5120-bit | ||
| Memory Bandwidth | 3TB/sec | 2TB/sec | 2TB/sec | 2TB/sec | ||
| VRAM | 80GB | 80GB | 80GB | 80GB | ||
| FP32 Vector | 60 TFLOPS | 48 TFLOPS | 19.5 TFLOPS | 19.5 TFLOPS | ||
| FP64 Vector | 30 TFLOPS | 24 TFLOPS | 9.7 TFLOPS (1/2 FP32 rate) |
9.7 TFLOPS (1/2 FP32 rate) |
||
| INT8 Tensor | 2000 TOPS | 1600 TOPS | 624 TOPS | 624 TOPS | ||
| FP16 Tensor | 1000 TFLOPS | 800 TFLOPS | 312 TFLOPS | 312 TFLOPS | ||
| TF32 Tensor | 500 TFLOPS | 400 TFLOPS | 156 TFLOPS | 156 TFLOPS | ||
| FP64 Tensor | 60 TFLOPS | 48 TFLOPS | 19.5 TFLOPS | 19.5 TFLOPS | ||
| Interconnect | NVLink 4 18 Links (900GB/sec) |
NVLink 4 (600GB/sec) |
NVLink 3 12 Links (600GB/sec) |
NVLink 3 12 Links (600GB/sec) |
||
| GPU | GH100 (814mm2) |
GH100 (814mm2) |
GA100 (826mm2) |
GA100 (826mm2) |
||
| Transistor Count | 80B | 80B | 54.2B | 54.2B | ||
| TDP | 700W | 350W | 400W | 300W | ||
| Manufacturing Process | TSMC 4N | TSMC 4N | TSMC 7N | TSMC 7N | ||
| Interface | SXM5 | PCIe 5.0 (Dual Slot) |
SXM4 | PCIe 4.0 (Dual Slot) |
||
| Architecture | Hopper | Hopper | Ampere | Ampere | ||
Meanwhile, NVIDIA’s flagship DGX systems, which are based on their HGX platform and are typically among the very first systems to ship, are now going to be among the last. NVIDIA is opening pre-orders for DGX H100 systems today, with delivery slated for Q1 of 2023 – 4 to 7 months from now. This is good news for NVIDIA’s server partners, who in the last couple of generations have had to wait to go after NVIDIA, but it also means that H100 as a product will not be able to put its best foot forward when it starts shipping in systems next month.
In a pre-briefing with the press, NVIDIA did not offer a detailed explanation as to why H100 has ended up delayed. Though speaking at a high level, company representatives did state that the delay was not for component reasons. Meanwhile, the company cited the relative simplicity of the PCIe cards for the reason that PCIe systems are shipping first; those are largely plug-and-play inside generic PCIe infrastructure, whereas the H100 HGX/SXM systems were more complex and took longer to finish.
There are some notable feature differences between the two form factors, as well. The SXM version is the only one that uses HBM3 memory (PCIe uses HBM2e), and the PCIe version requires fewer working SMs (114 vs. 132). So there is some wiggle room here for NVIDIA to hide early yield issues, if indeed that's even a factor.

Complicating matters for NVIDIA, the CPU side of DGX H100 is based on Intel’s repeatedly delayed 4th generation Xeon Scalable processors (Sapphire Rapids), which at the moment still do not have a release data completely nailed down. Less optimistic projections have It launching in Q1, which does align with NVIDIA’s own release date – though this may very well just be coincidence. Either way, the lack of general availability for Sapphire Rapids is not doing NVIDIA any favors here.
Ultimately, with NVIDIA unable to ship DGX until next year, NVIDIA's server partners aren't only going to beat them to the punch with PCIe-based systems, but they will be the first out the door with HGX-based systems as well. Presumably those initial systems will be using current-generation hosts, or possibly AMD’s Genoa platform if it’s ready in time. Among the firms slated to ship H100 systems are the usual suspects, including Supermicro, Dell, HPE, Gigabyte, Fujitsu, Cisco, and Atos.
Meanwhile, for customers who are eager to try out H100 before they buy any hardware, H100 is now available on NVIDIA’s LaunchPad service.
Finally, while we’re on the subject of H100, NVIDIA is also using this week’s GTC to announce an update to licensing for their NVIDIA AI Enterprise software stack. H100 now comes with a 5-year license for the software, which is notable since a 5 year subscription is normally $8000 per CPU socket.
Source: NVIDIA








8 Comments
View All Comments
Yojimbo - Tuesday, September 20, 2022 - link
My guess is the late arrival of Sapphire Rapids and Genoa have something to do with the delay. But it may also have to do with the US government's new restrictions on NVIDIA's China dealings. There were news reports that said "The company said the ban, which affects its A100 and H100 chips designed to speed up machine learning tasks, could interfere with completion of developing the H100, the flagship chip it announced this year." Perhaps NVIDIA's Chinese operations were key in the design and/or testing of the DGX servers.quorm - Tuesday, September 20, 2022 - link
Didn't Tom's hardware just have an article yesterday that Nvidia was diverting as many A100/H100 as possible to China before the ban takes effect? Maybe that explains this unusual release order.Yojimbo - Tuesday, September 20, 2022 - link
Could be. You think the Chinese are more interested in the HGX than the DGX? Supposedly, though, they wanted to release H100 earlier, and it hasn't been component shortages that have delayed the release. Why don't they have enough chips for both DGX and for server partners by now? Unless they were able to delay production with TSMC in some economically beneficial way (no guarantee of that).bernstein - Tuesday, September 20, 2022 - link
compared to the 4090 the H100 pcie looks pretty bad for FP-Vector stuff. at 83tflops the former is almost twice as fast... or is the 4090 artificially limited for fp64?Yojimbo - Tuesday, September 20, 2022 - link
The 4090 only has a small nunber of fp64 units for code compatability reasons. Its FP64 performance us abysmal because the hardware isn't on the chip.As far as theoretical max FP32 performance, the 4090 is of course a much better price/performance proposition. The two cards are for different segments. The H100 has HBM memory, 80 GB of memory, Nvlink capability, comes with 5 years of software licensing, and has been validated for servers, something that takes a significant outlay of money. You wouldn't buy an H100 PCIe for your desktop system if you're looking to do some ml training. you'd get a 4090. but if you wanted to move training to your datacenter, linking the compute resources across your entire organization and perhapaps scaling it to multiple gpus then you'd get H100s and the difference in cost would be well worth it. It would take a lot of expertise to get the 4090 to work like the h100 does out of the box and you wouldn't have access to nvidia's ai enterprise licenses or their support.
quorm - Tuesday, September 20, 2022 - link
It's interesting that for fp64 these are still nowhere near competitive with the MI250, particularly per watt. Guess all the new supercomputers using AMD were good decisions.Yojimbo - Tuesday, September 20, 2022 - link
Supercomputing is about more than FP64 these days (though that is still most important), and it's unclear what the real world application performance difference is using the MI250 architecture, which seems to double up on FP64 execution units. I'm not sure exactly what they are doing, but it may be similar to the doubled up FP32 units NVIDIA implemented on Ampere. That didn't result in a proportional increase of performance in games, though in rendering tasks it seemed to maintain a better computational efficiency than for gaming. If that is what AMD did, I don't know how it plays out in HPC.But yes, NVIDIA isn't willing to downgrade their tensor cores for the benefit of FP64. NVIDIA makes billions of dollars per year from AI-related data center business. Supercomputing is a drop in the bucket compared to that. AMD and Intel, on the other hand, don't have much of a data center GPU compute business and are looking to break into the game through winning supercomputer contracts. Whether those decisions to go with AMD and Intel were good ideas, though, will take some more time to determine, I think.
gue2212 - Friday, October 28, 2022 - link
I thought I had heard Nvidia's Grace ARM CPUs would go with Hopper!?