Imagination Goes Further Down the AI Rabbit Hole, Unveils PowerVR Series3NX Neural Network Accelerator
by Nate Oh on December 4, 2018 7:00 AM EST 28.11.18-01_678x452.png)
After Imagination first announced their PowerVR Series2NX Neural Network Accelerator (NNA) last September, it has become a key part in their ambitions for AI and neural networks on the edge, with smaller devices intended for inferencing. So along with their new Series9X-P GPUs, Imagination is taking the next major step in their neural networking journey, announcing the PowerVR Series3NX Neural Network Accelerator (NNA) and its family of IP cores, as well as a programmable 3NX-F IP configuration containing a 3NX NNA, Rogue GPGPU, and local memory.
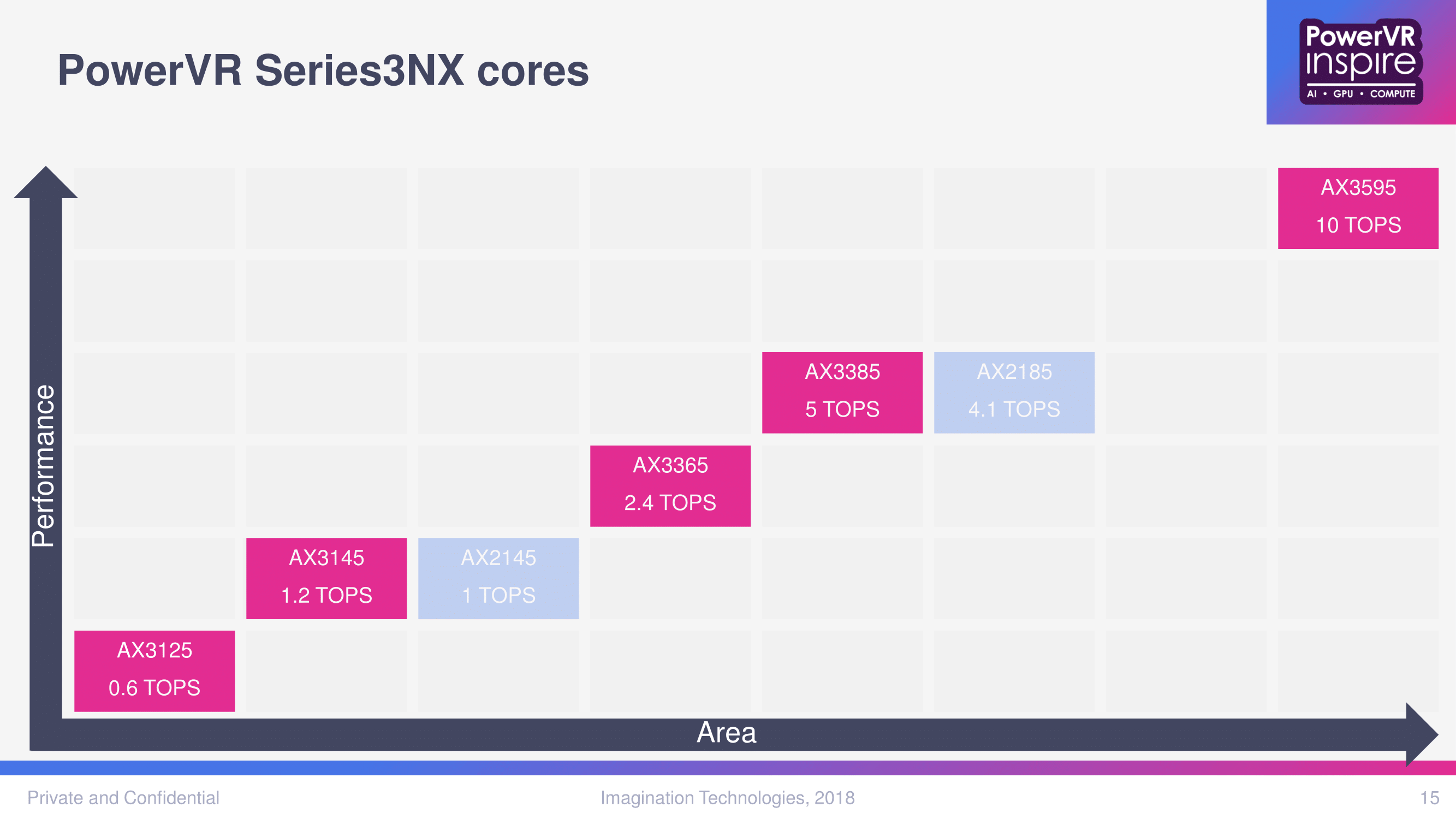
At a glance, today’s full lineup is in sharp contrast to the original 2NX announcement. Imagination continued to work with lead customers on an unannounced 1st generation silicon IP, and it was only around 9 months later that the first 2NX IP cores were launched, with 2 single core options. Here, the 3NX is launching with 5 single core options, 4 multi-core instances (2-, 4-, 8-, and 16-core), and a special programmable and ‘flexible’ variant in the 3NX-F. And while everything about the 2NX architecture was new by nature, the 3NX microarchitectural details were – and are – sparse, though the 3NX itself was outed earlier by its presence on the automotive IP roadmap, as well as being briefly mentioned at 2018 Andes RISC-V Con in Beijing last month.
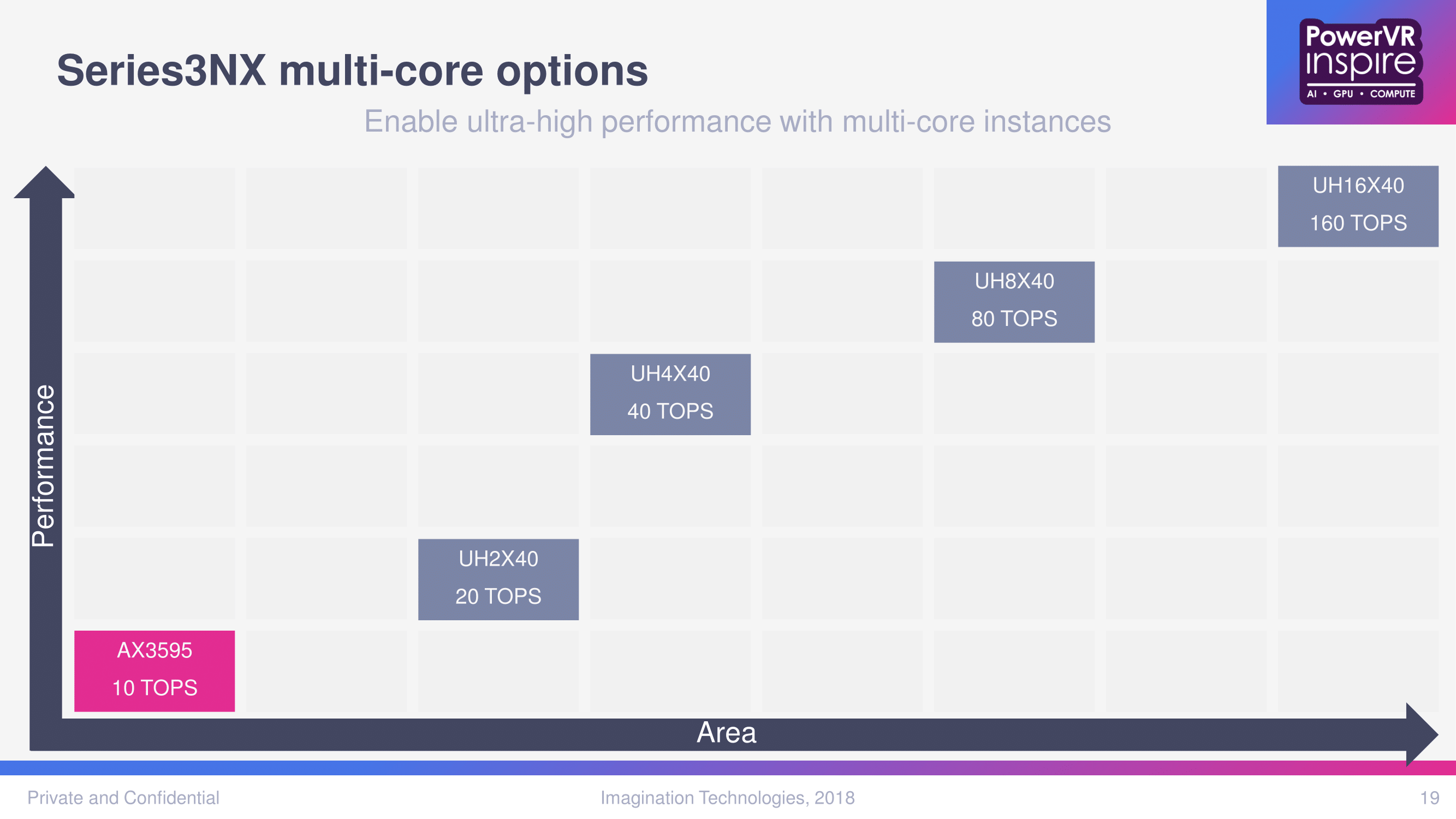
In terms of straight performance numbers, the most performant IP core, AX3595, is stated to be 10 TOPS. And so when scaled up to a 16-core instance, a maximum 160 TOPS.

While most of the architectural improvements over the 2NX were unspecified, the 3NX introduces a new lossless compression scheme for weights, with greater benefits at lower bit-depths. By reducing the size of the neural network model, bandwidth and memory usage is reduced.
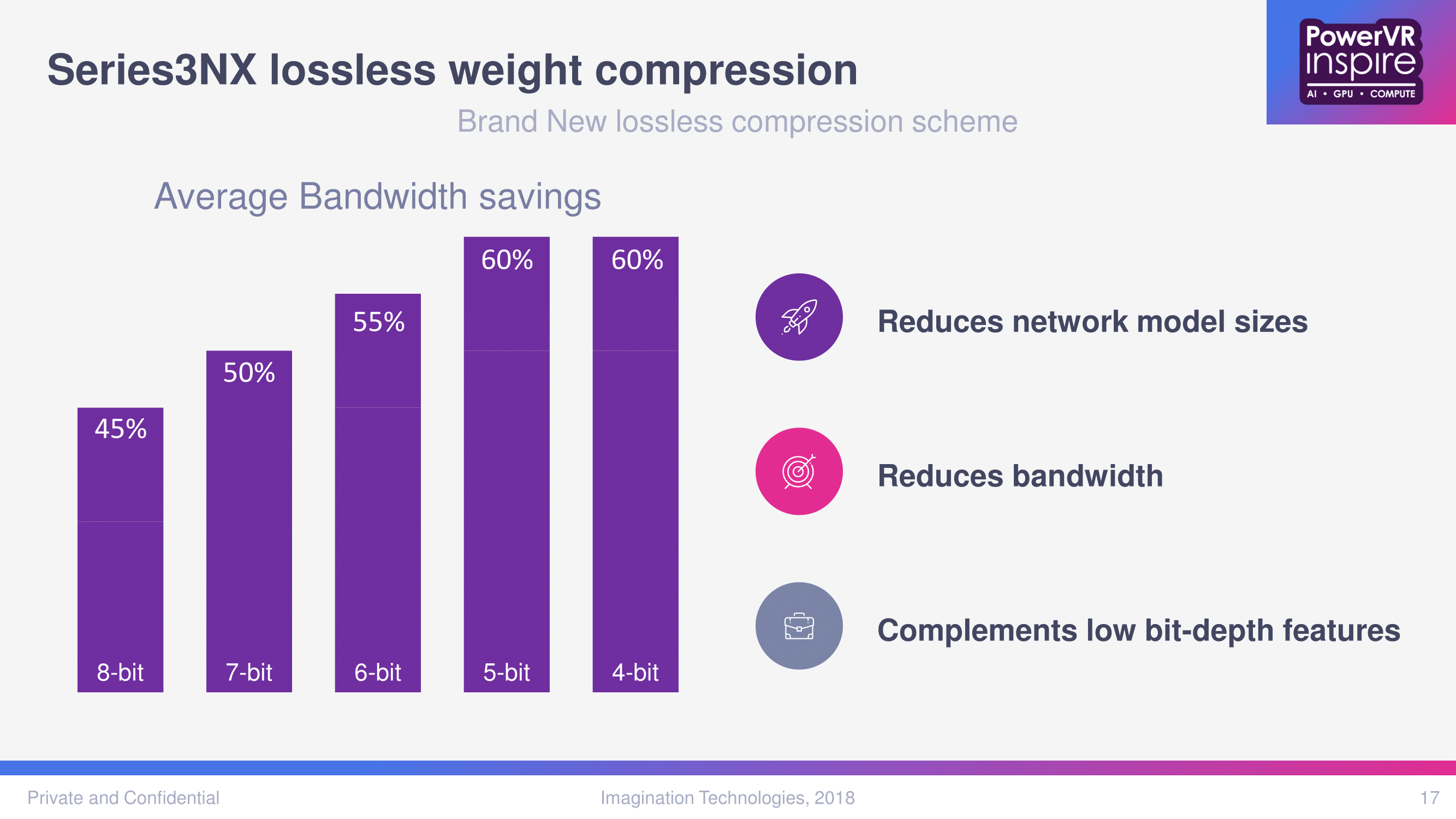
Looking at the disclosed performance numbers, the peak 4096 MACs/clock for a presumably single 3NX core is double the 2NX’s 2048 MACs/clock. For the 2NX, this was achieved by its maximum of 8 compute engines on 256x8-bit MACs, with multi-core being the route to higher MACs/clock. For the 3NX core, however, it’s not clear if the same 8 compute engine maximum applies.
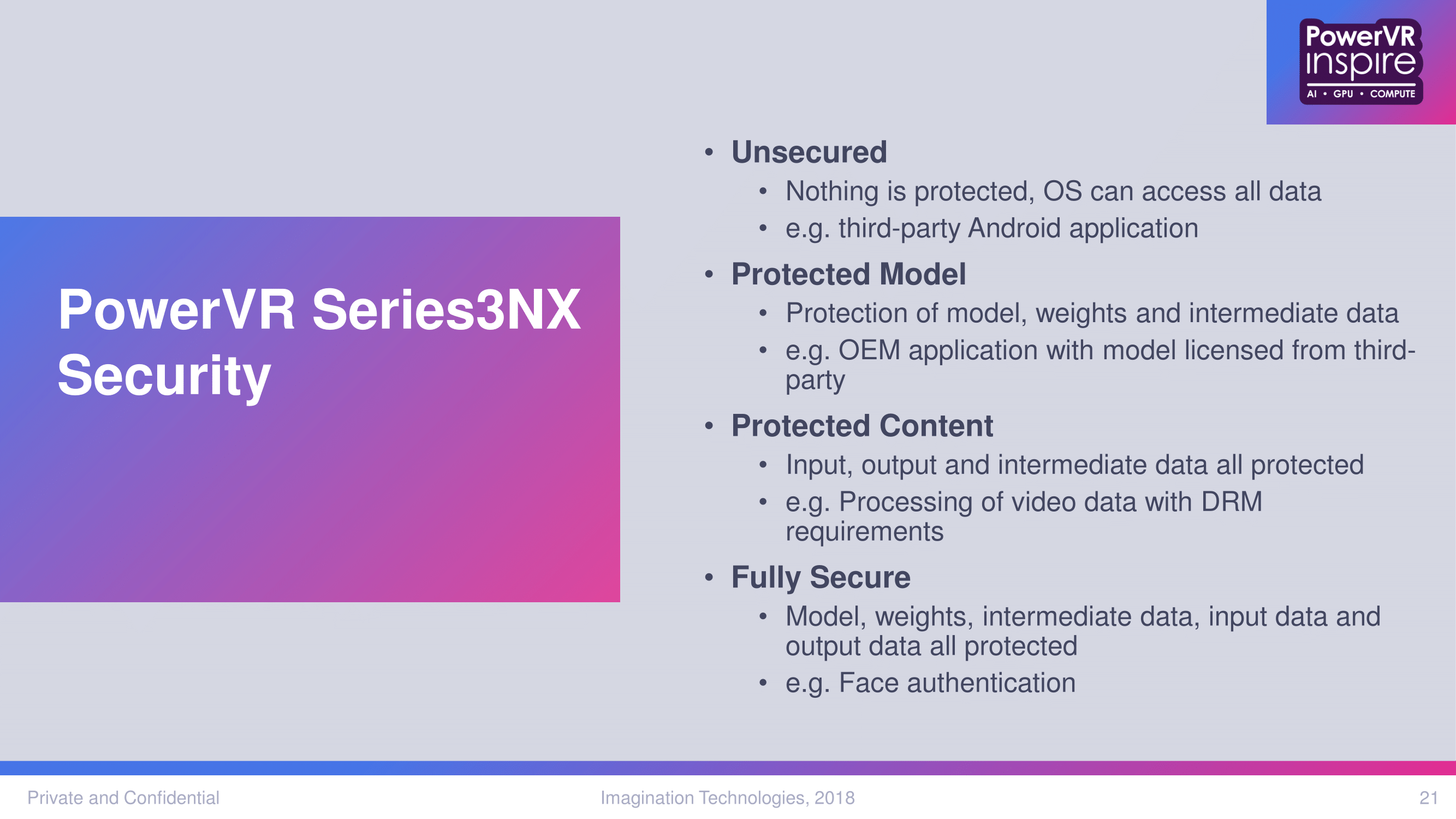
The 3NX also brings new hardware-level security with TrustZone support, a ‘flexible security architecture’, and support for up to 3 independent security zones (worlds). For the 3NX NNA, configurations might secure only the neural network model, weights, and any intermediate data; only the input/output and intermediate data; or all of the above.

Given Imagination’s emphasis on the PowerVR GPU + 2NX NNA pairing, it was only a matter of time before the company brought something like the 3NX-F IP configuration. In sum, it is essentially a self-contained combination of 3NX, a Rogue-based GPGPU (NNPU), and local DRAM, all of which interfaces via a fabric interconnect. For now, the 3NX-F is only available as a single-core instance, though Imagination is working with vendors on multi-core 3NX-F options as well. With its ‘NNPU’, the dedicated in-unit GPGPU optimized for neural network compute, the 3NX-F is bringing extensible programmability and floating-point support, taking advantage of OpenCL/SYCL and Imagination’s ongoing API/devkit/toolchain work on that front.
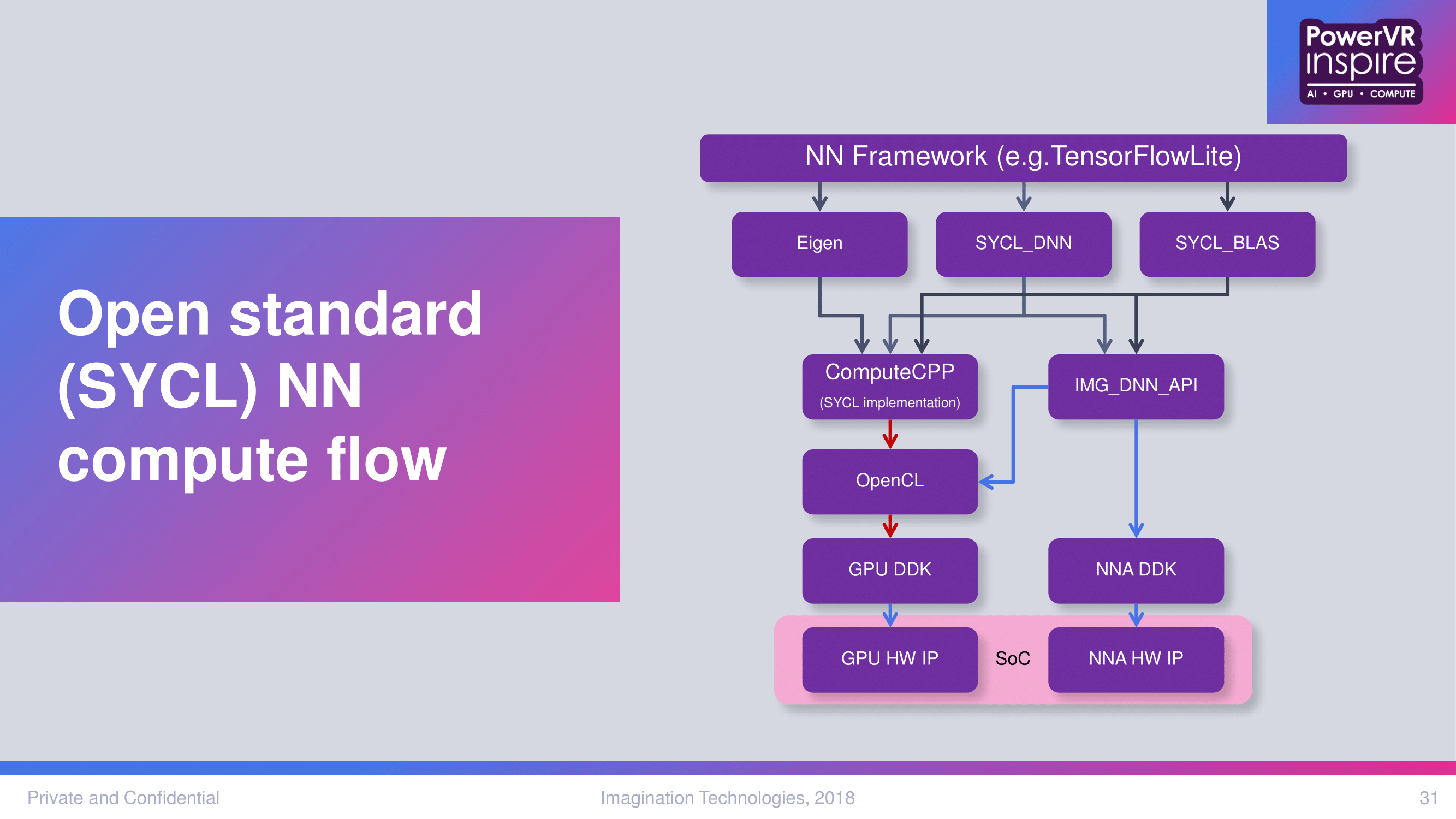
Strictly-speaking, the SeriesNX NNA doesn’t supplant neural network computing on GPUs, given the variety of DL/NN use-cases, silicon designs, and inherent programmability of GPUs. Instead, as a supplemental component for NN compute, the relatively fixed-function NNA would be constantly communicating with the primary NN compute component, ostensibly the GPU. So integrating these IP blocks in a self-contained way can offer silicon designers an extra degree of tuning and optimization flexibility and in a potentially lower power envelope or smaller silicon footprint. Certain applications would be well suited for a dedicated neural network accelerating block without meriting a separate GPU; Imagination brought up ‘smart surveillance’ as an example where there would be no need to render pixels on the SoC. And even with host GPUs, the compute-isolated 3NX-F wouldn’t need to compete with those resources.
Beyond the SIP core, the multi-core 3NX scaling and the ‘NN-compute-on-block’ 3NX-F raises questions on the nature of the interconnect, but implementation details on the proprietary fabric are sparse at this time.
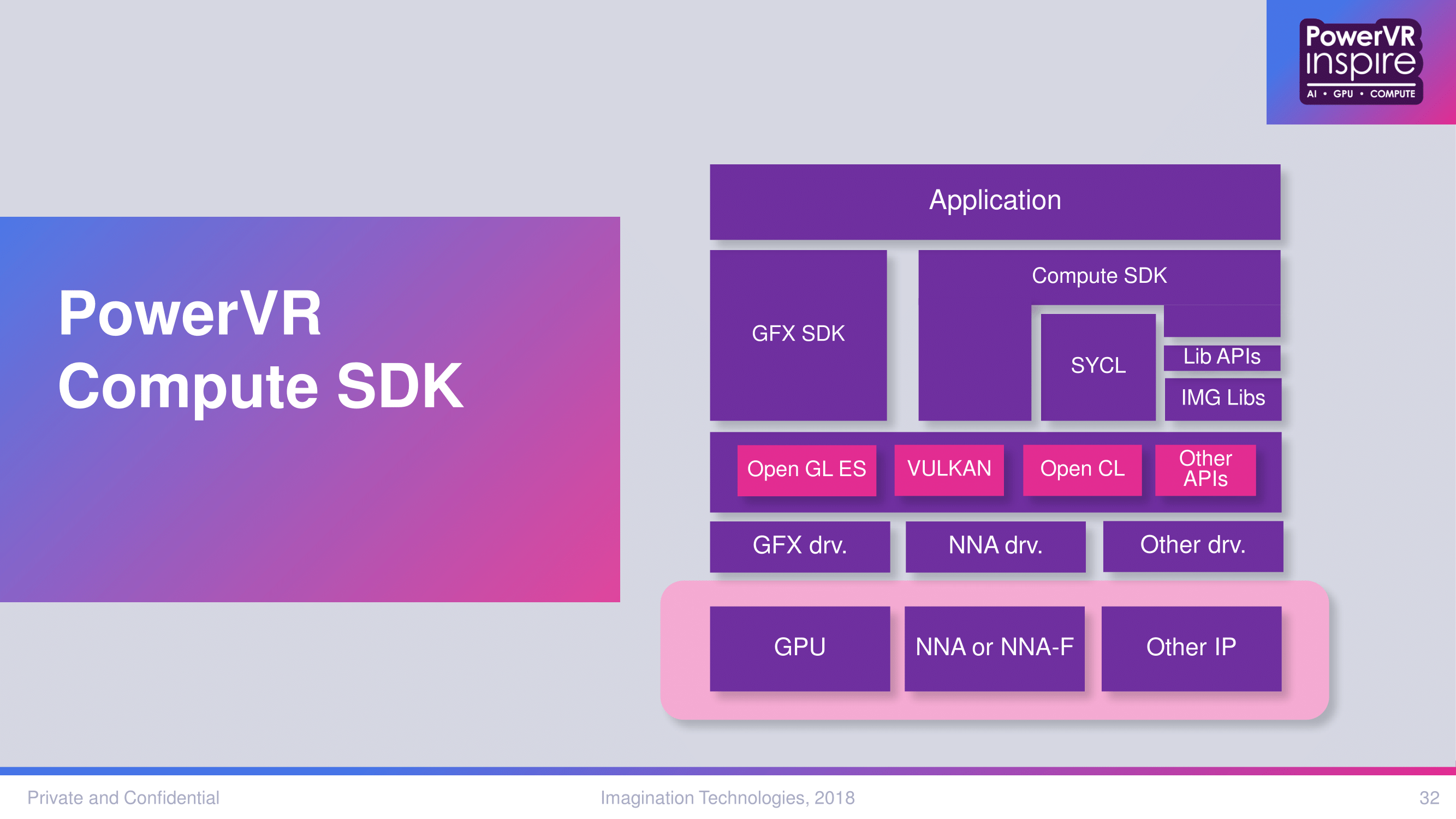
In combination with the silicon IP is not just a Compute SDK particularly of value to the 3NX-F, but also the 'Ecosystem Partnership Program.' The SDK naturally builds on Imagination’s IP and supported libraries, as well as 3NX/3NX-F development kits, but also on open APIs and third-party libraries. To that end, for IPs like the 3NX NNA and especially the 3NX-F, the usual hands-off approach for a pure IP licensor is less effective in guiding solutions to market, and Imagination noted being asked by SoC vendors regarding the right IP vendors, and vice versa. So Imagination is taking a more assertive and proactive role in the early days of their own ecosystem, getting various firms in touch with each other, managing the distribution of devkits, and connecting IP vendors who would provide libraries and kernels needed by SoC vendors. Or perhaps more pithily summed up as a sort of matchmaking service.
The Series3NX cores are available for licensing and are launching in roughly 2 weeks, while the 3NX-F IP is planned to be available in Q1 2019.
 28.11.18-01_thumb.png)
 28.11.18-02_thumb.png)
 28.11.18-03_thumb.png)
 28.11.18-04_thumb.png)
 28.11.18-05_thumb.png)
 28.11.18-06_thumb.png)








0 Comments
View All Comments