Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTSoC Tile, Part 2: NPU Adds a Physical AI Engine
The last major block on the SoC tile is a full-featured Neural Processing Unit (NPU), a first for Intel's client-focused processors. The NPU brings AI capabilities directly to the chip and is compatible with standardized program interfaces like OpenVINO. The architecture of the NPU itself is multi-engine in nature, which is comprised of two neural compute engines that can either collaborate on a single task or operate independently. This flexibility is crucial for diverse workloads and potentially benefits future workloads that haven't yet been optimized for AI situations or are in the process of being developed. Two primary components of these neural compute engines stand out: the Inference Pipeline and the SHAVE DSP.

The Inference Pipeline is primarily responsible for executing workloads in neural network execution. It minimizes data movement and focuses on fixed-function operations for tasks that require high computational power. The pipeline comprises a sizable array of Multiply Accumulate (MAC) units, an activation function block, and a data conversion block. In essence, the inference pipeline is a dedicated block optimized for ultra-dense matrix math.
The SHAVE DSP, or Streaming Hybrid Architecture Vector Engine, is designed specifically for AI applications and workloads. It has the capability to be pipelined along with the Inference Pipeline and the Direct Memory Access (DMA) engine, thereby enabling parallel computing on the NPU to improve overall performance. The DMA Engine is designed to efficiently manage data movement, contributing to the system's overall performance.
At the heart of device management, the NPU is designed to be fully compatible with Microsoft's new compute driver model, known as MCDM. This isn't merely a feature, but it's an optimized implementation with a strong emphasis on security. The Memory Management Unit (MMU) complements this by offering multi-context isolation and facilitates rapid and power-efficient transitions between different power states and workloads.

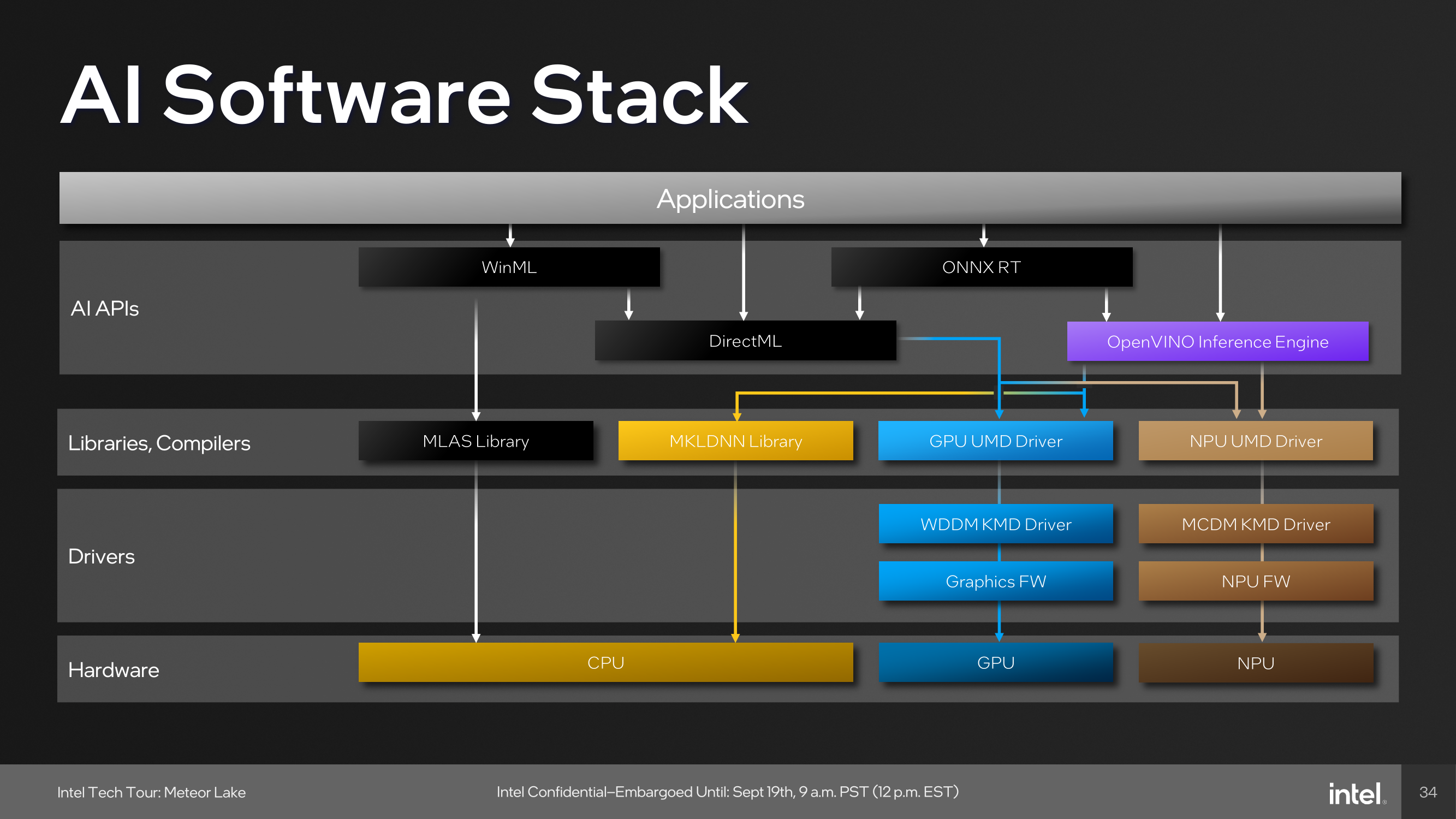
As part of building an ecosystem that can capitalize on Intel's NPU, they have been embracing developers with a number of tools. One of these is the open-source OpenVINO toolkit, which supports various models such as TensorFlow, PyTorch, and Caffe. Supported APIs include Windows Machine Learning (WinML), which also includes the DirectML component of the library, the ONNX Runtime accelerator, and OpenVINO.
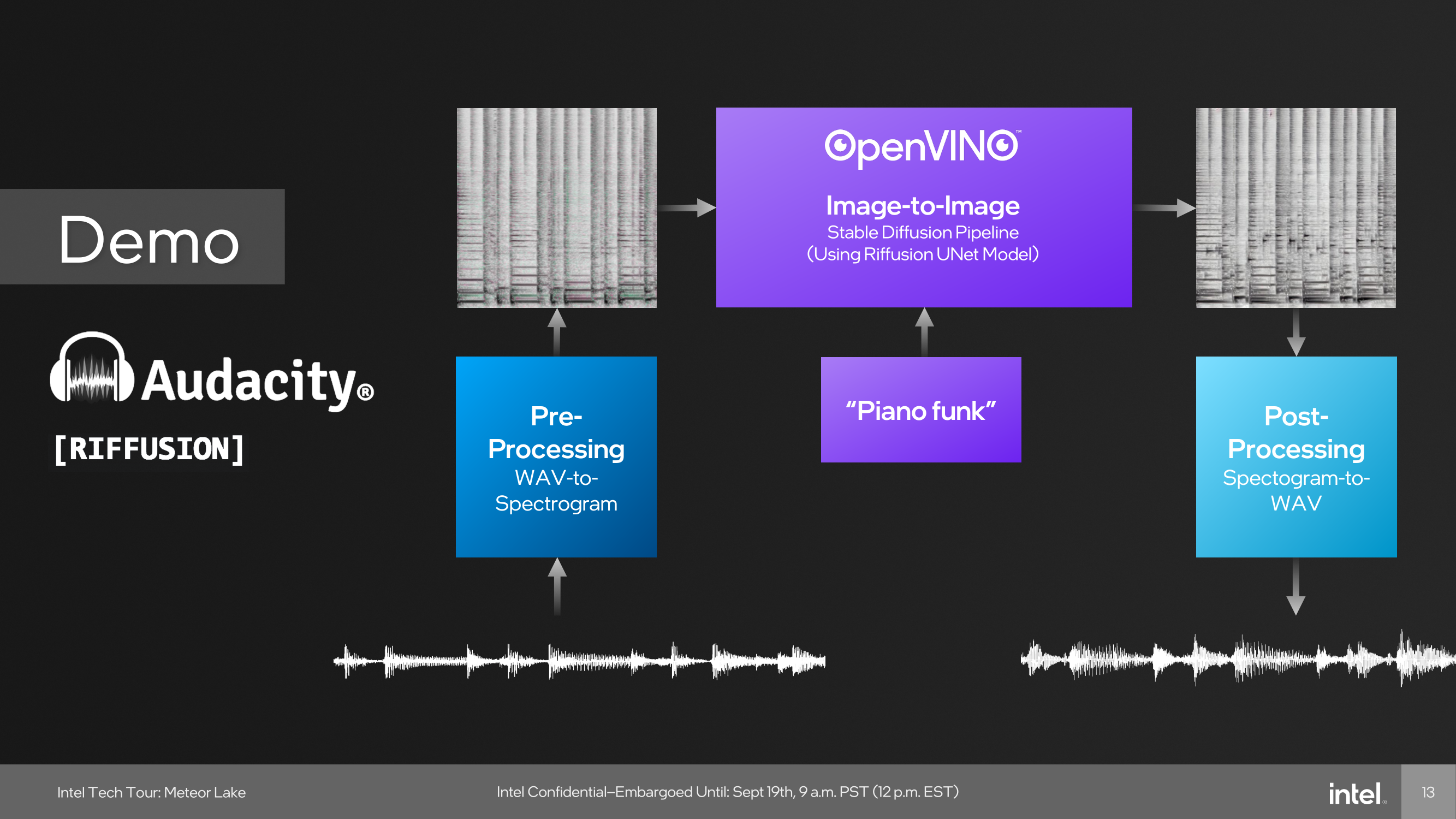
One example of the capabilities of the NPU was provided through a demo using Audacity during Intel's Tech Tour in Penang, Malaysia. During this live demo, Intel Fellow Tom Peterson, used Audacity to showcase a new plugin called Riffusion. This fed a funky audio track with vocals through Audacity and separated the audio tracks into two, vocals and music. Using the Riffusion plugin to separate the tracks, Tom Peterson was then able to change the style of the music audio track to a dance track.
The Riffusion plugin for Audacity uses Stable Diffusion, which is an open-source AI model that traditionally generates images from text. Riffusion goes one step further by generating images of spectrograms, which can then be converted into audio. We touch on Riffusion and Stable Diffusion because this was Intel's primary showcase of the NPU during Intel's Tech Tour 2023 in Penang, Malaysia.
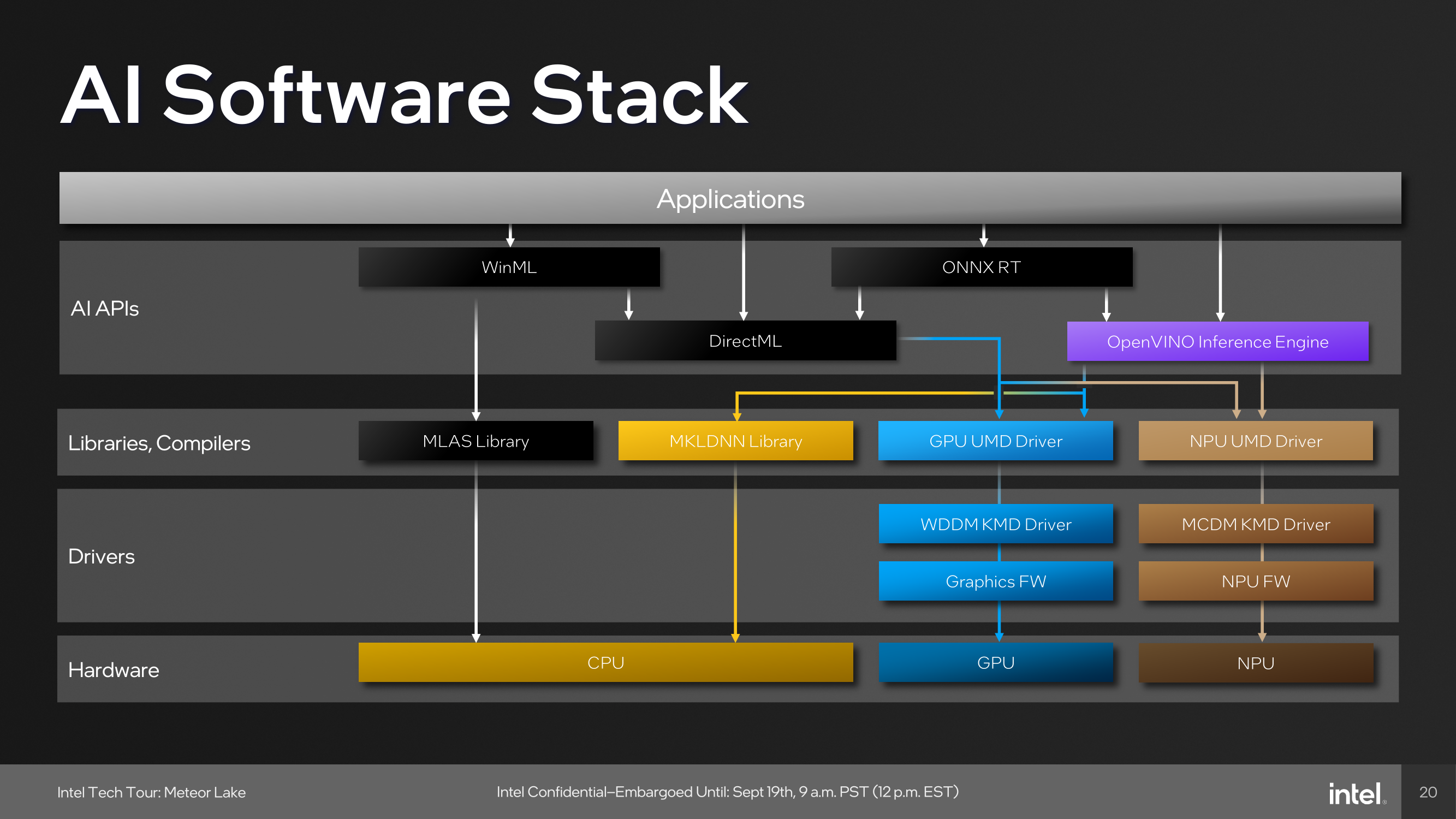
Although it did require resources from both the compute and graphics tile, everything was brought together by the NPU, which processes multiple elements to spit out an EDM-flavored track featuring the same vocals. An example of how applications pool together the various tiles include those through WinML, which has been part of Microsoft's operating systems since Windows 10, typically runs workloads with the MLAS library through the CPU, while those going through DirectML are utilized by both the CPU and GPU.
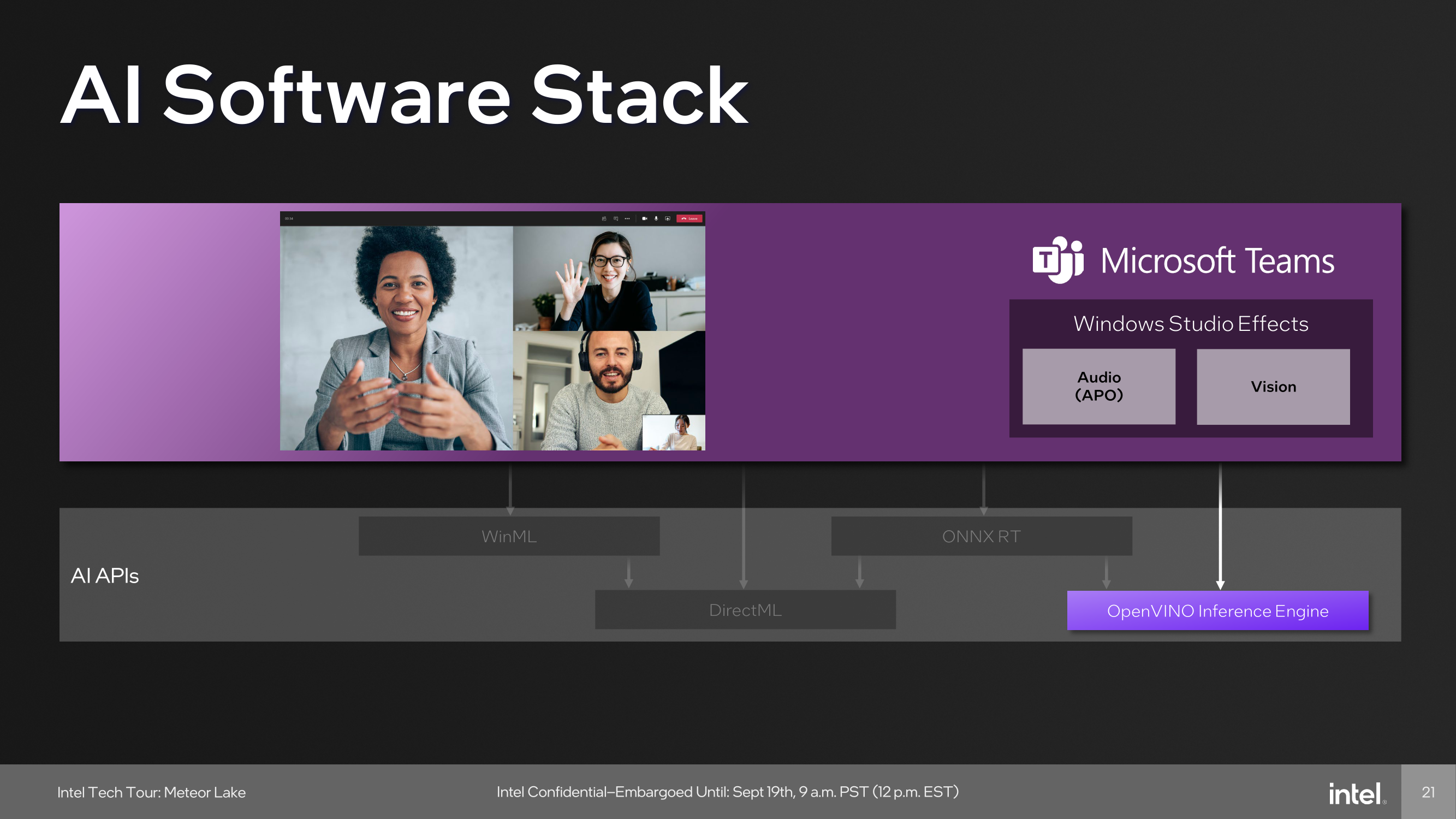
Other developers include Microsoft, which uses the capability of the NPU in tandem with the OpenVINO inferencing engine to provide cool features like speech-to-text transcripts of meetings, audio improvements such as suppressing background noise, and even enhancing backgrounds and focusing capabilities. Another big gun using AI and is supported through the NPU is Adobe, which adds a host of features for adopters of Adobe Creative applications use. These features include generative AI capabilities, including photo manipulative techniques in Photoshop such as refining hair, editing elements, and neural filters; there's a lot going on.








107 Comments
View All Comments
erinadreno - Tuesday, September 19, 2023 - link
Chiplets on mobile processors doesn't sound exactly enticing. Why does Intel feel the need to use 3 different types of chiplets from 2 foundries on a power-sensitive mobile chip?jazzysoggy - Tuesday, September 19, 2023 - link
It's not the same chiplet strategy as AMD is using for Zen, it's more inline with AMD's MI accelerators. Not as cheap as the Zen strategy, but much more power efficient for power sensitive mobile chips.schujj07 - Tuesday, September 19, 2023 - link
Do you have proof it is more power efficient? Intel right now is vastly less power efficient than AMD and that is regardless of chiplet or monolithic dies.Unashamed_unoriginal_username_x86 - Tuesday, September 19, 2023 - link
First page says .15-.3 pJ/bit for Foveros, AMD has previously stated infinity fabric uses "<2 pJ/bit" which presumably isn't very far under 2. this puts Intel at 5-10x the efficiency for this very specific part of data transmissionduploxxx - Wednesday, September 20, 2023 - link
first generations of infinity fabric were also less power hungry, untill they noticed what is needed to get things faster and there you go. Lots of bandwidth changes and infinity fabric changes and as well the power usage... lets see what Intel is capable of doing first, it's marketing all over the place...Samus - Tuesday, September 19, 2023 - link
Intel is behind AMD on power efficiency purely due to process node. Architecturally they are quite competitive. This is proven in how AMD performance scales when underclocked compared to Intel.Anandtech recently did an investigation into this and came to the conclusion that while the architectures are vastly different they have potentially similar performance once you determine the ideal wattage for the chip, and at the moment Intel is pushing high TDP into extremely inefficient territory to have something competitive with AMD, due to AMD being on a superior node. Basically AMD can deliver X performance at 56w while Intel can deliver X performance at 72w, but Intel can deliver Y performance at 100w while AMD delivers Y performance at 95w.
While impossible to absolutely prove, various factors can help determine this differential has more to do with manufacturing superiority than design superiority.
Intel going for tiles here is a clear attempt to close the gap on this.
PeachNCream - Thursday, September 21, 2023 - link
I think I'd second-guess anything Anandtech does these days. They had one person with an advanced degree that departed years ago after being bought out by Qualcomm when they owned Killer NICs and have since had trouble publishing articles without obvious typos and "in-a-hurry" oversights.On the other hand, if that data is supported by a more credible publisher that has decent measuring equipment and can afford to purchase its own test hardware rather than relying solely on free samples - well then we should sit up and take notice. At this point though, an Anandtech exclusive is just a reason to raise the citation needed flag and THEN further analyze the sources for their motives.
RedGreenBlue - Sunday, October 1, 2023 - link
They’ve always had typos that slip through, or grammar mistakes. All the way back to Anand’s time. I don’t like it but I know what was intended when I see one. There still isn’t another website with the same focus on the segments they focus on. I miss the deep-dives into mobile chips and phones they used to do by investigating what wasn’t publicly released about things but for most people that’s a niche purpose that other sites cover extensively with reviews and can focus on and is a bit too consumer focused and easily found elsewhere. Not really their target market.Composite - Thursday, September 28, 2023 - link
This is indeed similar to MI250 2.5D fabric. However, MI300X is full 3D fabric.elmagio - Tuesday, September 19, 2023 - link
My personal guess, from the moment this was announced, has been that they want every single cm² of silicon going through their Intel 4/EUV capacity going to the compute tile. They're lagging quite a bit behind TSMC and Samsung in terms of EUV capacity, so anything that doesn't stand to benefit much from being designed from the ground up to be made on their own nodes is worth offloading to TSMC.SoC and IO tiles are really not process-limited currently, and their Arc GPUs are in general going manufactured elsewhere anyway. But their CPU design process has always been fully in house every step of the way, and they don't want to change that (at least not yet). So everything but compute would be "wasted" Intel 4 capacity.