Intel Core i9-13900K and i5-13600K Review: Raptor Lake Brings More Bite
by Gavin Bonshor on October 20, 2022 9:00 AM ESTSPEC2017 Multi-Threaded Results
Single-threaded performance is only one element in regard to performance on a multi-core processor, and it's time to look at multi-threaded performance in SPEC2017. Although things in the single-threaded SPEC2017 testing showed that both Zen 4 and Raptor Lake were consistently at loggerheads, let's look at data in the Rate-N multi-threaded section.
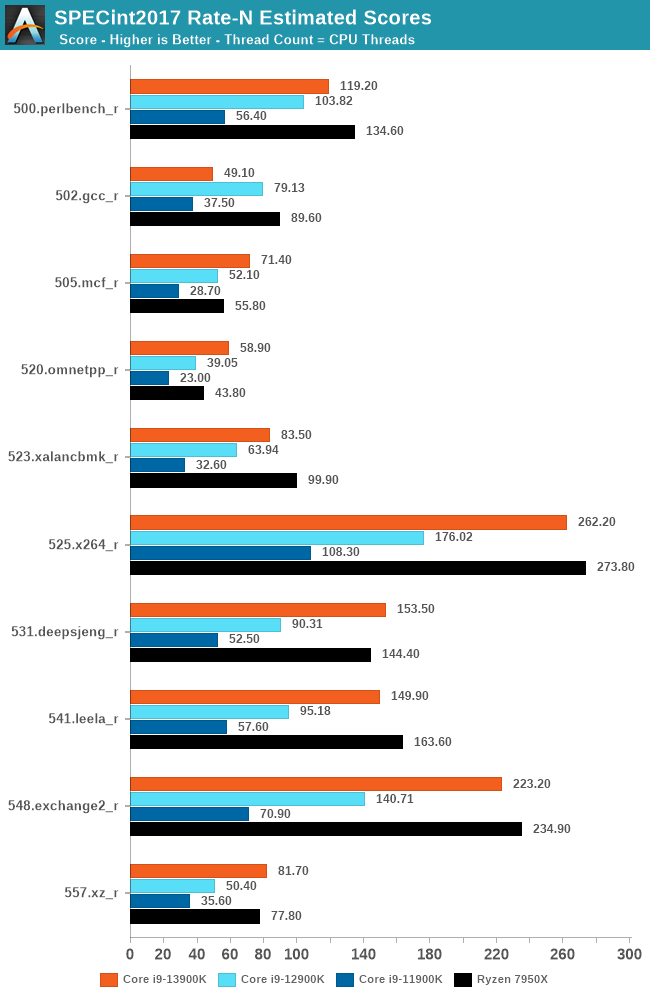
Looking at the data in our first part of SPEC2017 (int) nT testing, we're seeing similar trade-offs between Raptor Lake (13th Gen) and Zen 4 (Ryzen 7000) platforms. While Raptor Lake won in the 500.perlbench_r single-threaded test, Zen 4 has the lead by around 13% in multi-threaded performance, despite the Core i9-13900K having eight more physical cores (albeit efficiency cores).
One stand-out part of our SPECint2017 multi-threaded testing is just how far ahead the Core i9-13900K is ahead of the previous Core i9-12900K in multi-threaded tests. This comes thanks to more cores (2x the E-cores), and higher turbo frequencies. For example, in the 525.x264_r test, the Core i9-13900K is nearly 50% better than the i9-12900K; the only part where Raptor Lake failed to outperform Alder Lake was in the 502.gc_r test.
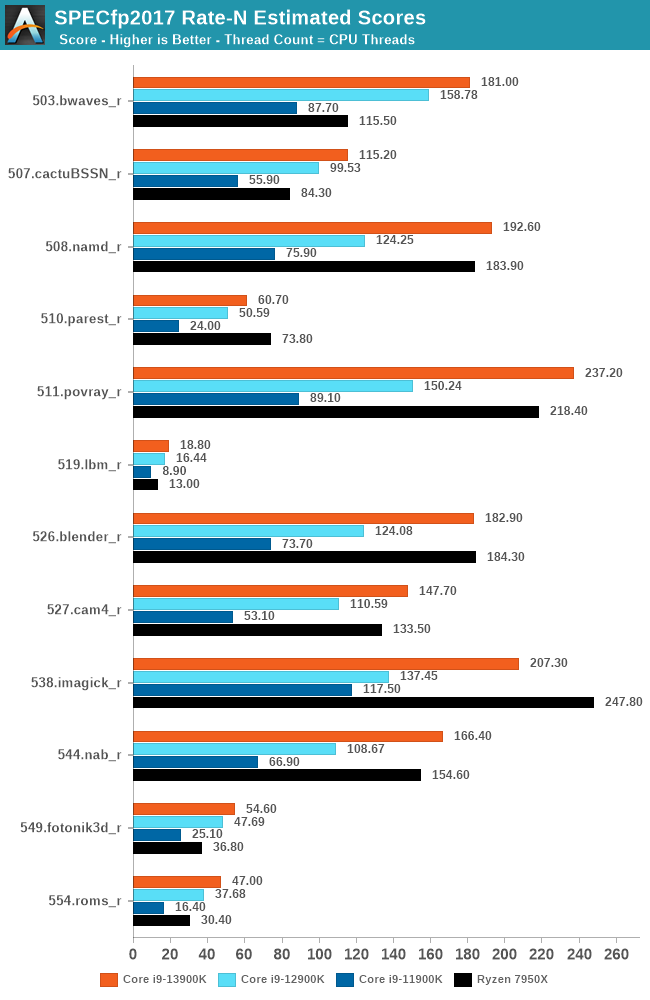
Moving onto the second half of our SPEC2017 multi-threaded results (Floating Point), the Core i9-13900K really does show itself to be a formidable force compared to Zen 4. In the majority of SPECfp2017 tests, the Core i9-13900K is ahead in multi-threaded performance. The improvements in overall performance from Rocket Lake (11th Gen) to Alder Lake were decent, but the improvement from Rocket Lake last year in Q1 2021 to Raptor Lake today – a more useful metric for the usual 2-4 year hardware upgrade cycle – is very impressive indeed.
Summarizing the SPEC2017 multi-threaded results, in some areas Zen 4 is the winner, some areas Raptor Lake (Raptor Cove + Gracemont) is the winner. It is incredibly close in quite a few of the tests, and without sounding negative on the Zen 4 architecture here, but Intel has done a very good job bridging that initial gap to make things competitive against AMD's best.
Update 18/07/23
Following on from our initial results in our SPECint2017 Rate multi-threaded testing of the Core i9-13900K, we wanted to investigate the 502.gcc_r result, which we believed to be an anomaly of sorts. We observed a score of 49.1 on the Core i9-13900K, which, compared to the previous generation Core i9-12900K, is a regression in performance; the result was around 37% lower than the previous generation.
To investigate further, we've re-tested the Core i9-13900K using SPEC2017 Rate to identify any issues and to see if we could further replicate the issue or, at the very least, provide a more up-to-date list of results.
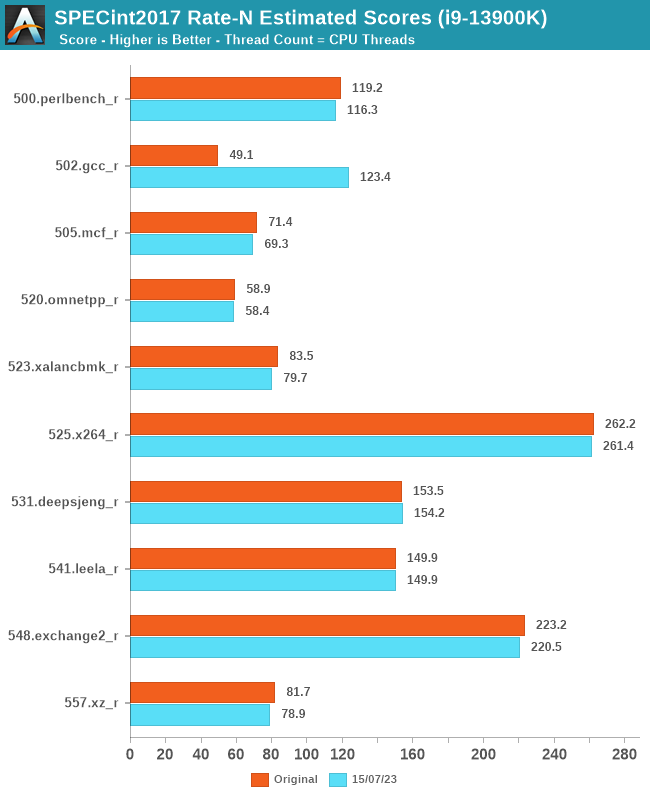
Looking at our updated SPECin2017 results, we are comparing the original Core i9-13900K data to the new data for comparative purposes. Although the results are very similar in many cases, we can see some slight regression in a few results, which could be attributed to various factors, including Windows 11's scheduler, power budget, or just general variance in running.
The biggest highlight of our re-test is the 502.gcc_r result, which seems to be an anomaly for the original run. We've run SPEC2017 numerous times to confirm that the above results are exactly where they should be.
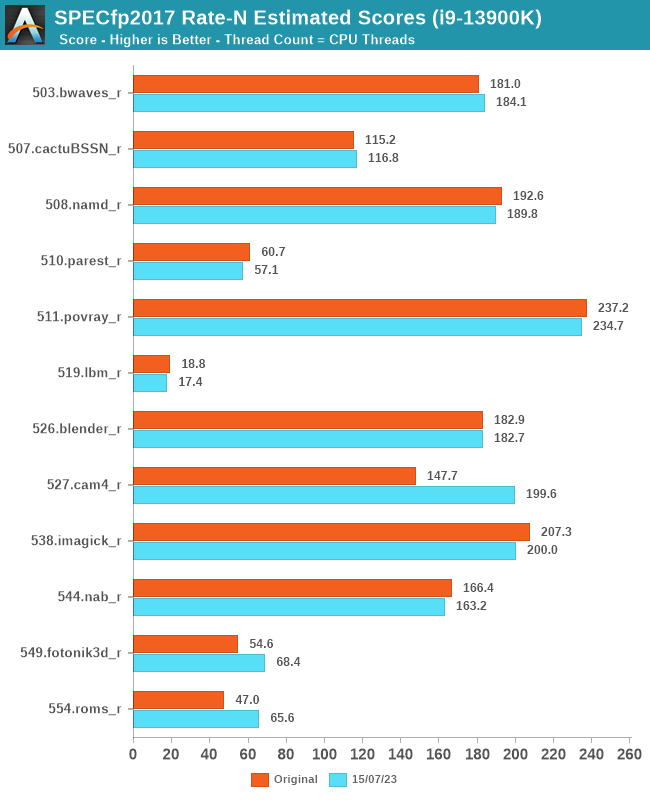
Focusing on our latest results for SPECfp2017 Rate N, we can see a similar story, with very similar results in multi-threaded SPEC2017 performance as with our original testing. In fact, a couple of the results yielded slightly higher results, which could be simply down to scheduler maturity, OS-related improvements including the scheduler, or overall firmware maturity. The results include 527.cam4_r, 549.fotonik3d_r, and 554.roms_r, which show better gains in our latest testing, especially compared to the Core i9-12900K, which this chip replaced in the market.
The biggest takeaway from our re-testing is the updated SPECint2017 Rate-N result for 502.gcc_r, which shows that our original results were nothing more than an anomaly, and we've been unable to replicate the issue.
Update: 07/22/23
We are aware of potential issues with memory capacity, and as such, we are re-running the Core i9-13900K with higher capacity DDR5 memory at JEDEC settings relevant to the platform. We have done a run with 64 GB instead of the regular 32 GB, which with the Core i9-13900K is 2 GB per thread (2 GB x 32 = 64 GB). Looking at preliminary results, we aren't seeing any major variances in these results.








169 Comments
View All Comments
Nero3000 - Thursday, October 20, 2022 - link
Correction: the 12600k is 6P+4E - table on first pageHixbot - Thursday, October 20, 2022 - link
I am hoping for an high frequency 8 core i5 with zero ecores and high cache. It's would be a gamer sweet spot, and could counter the inevitable 3d cache Zen 4.nandnandnand - Friday, October 21, 2022 - link
big.LITTLE isn't going away. It's in a billion smartphones, and it will be in most of Intel's consumer CPUs going forward.Just grab your 7800X3D, before AMD does its own big/small implementation with Zen 5.
HarryVoyager - Friday, October 21, 2022 - link
Honestly, I'm underwhelmed by Intel's current big.LITTLE setup. As near as I can tell, under load the E cores are considerably less efficient than the P cores are, and currently just seem to be there so Intel can claim multi-threading victories with less die space.And with the CPU's heat limits, it just seems to be pushing the chip into thermal throttling even faster.
Hopefully future big.LITTLE implementations are better.
nandnandnand - Friday, October 21, 2022 - link
Meteor Lake will bring Redwood Cove to replace Golden/Raptor Cove, and Crestmont to replace Gracemont. Gracemont in Raptor Lake is the same as in Alder Lake except for more cache, IIRC. All of this will be on "Intel 4" instead of "Intel 7", and the core count might be 8+16 again.Put it all together and it should have a lot of breathing room compared to the 13900K(S).
8+32 will be the ultimate test of small cores, but they're already migrating on down to the cheaper chips like the 13400/13500.
Hixbot - Saturday, October 22, 2022 - link
Yes it does seem backwards that the more efficient architecture is in the P core. Reducing power consumption for light tasks seems better to keep it on the P core and downclock. I don't see the point of the "e" cores as effiency, but rather academic multithreaded benchmark war. Which isn't serving the consumer at all.deil - Monday, October 24, 2022 - link
E is still useful, as you get 8/8 cores in space where you could cram 2/4. I agree E for efficiency should be B as background to make it clearer what's the point. They are good for consumers as they offer all the high speed cores for main process, so OS and other things dont slow down.I am not sure if you followed, but intel cpu's literally doubled in power since they appeared, and at ~25% utilization, cpu's halved power usage. What you should complain about is bad software support, as this is not something that happens in the background.
TEAMSWITCHER - Monday, October 24, 2022 - link
I don't think you are fully grasping the results of the benchmarks. Compute/Rendering scores prove that e-cores can tackle heavy work loads. Often trading blows with AMD's all P-Core 7950X, and costing less at the same time. AMD needs to lower all prices immediately.haoyangw - Monday, October 24, 2022 - link
That's an oversimplification actually, P-cores and E-cores are both efficient, just for different tasks. The main efficiency gain of P-cores is it's much much faster than E-cores for larger tasks. Between 3 and 4GHz, P-cores are so fast they finish tasks much earlier than e-cores so total energy drawn is lower. But E-cores are efficient too, just for simple tasks(at low clockspeeds). Below 3GHz and above 1GHz, e-cores are much more efficient, beating P-cores in performance while drawing less power.Source: https://chipsandcheese.com/2022/01/28/alder-lakes-...
Great_Scott - Friday, November 25, 2022 - link
Big.LITTLE is hard to do, and ARM took ages and a lot of optimization before phone CPUs got much benefit from it.The problem of the LITTLE cores not adding anything in the way of power efficiency is well-known.
I'm saddened that Intel is dropping their own winning formula of "race-to-sleep" that they've successfully used for decades for aping something objectivly worse because they're a little behind in die shrinking.