AMD Threadripper Pro Review: An Upgrade Over Regular Threadripper?
by Dr. Ian Cutress on July 14, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- ThreadRipper
- Threadripper Pro
- 3995WX
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
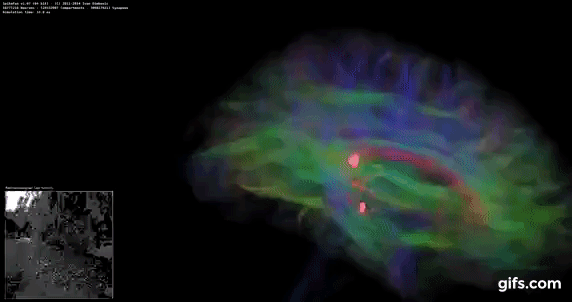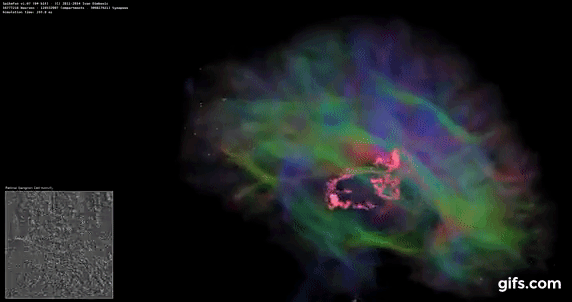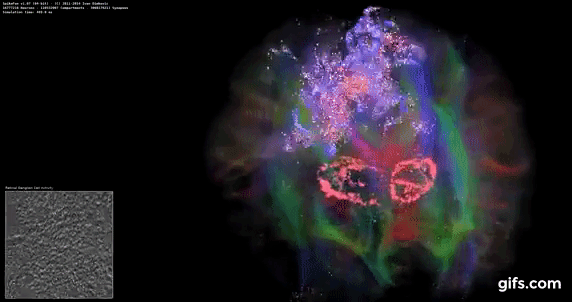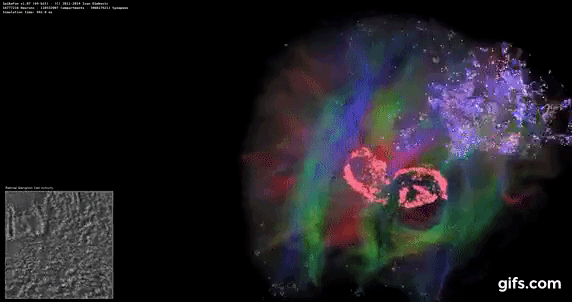
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.
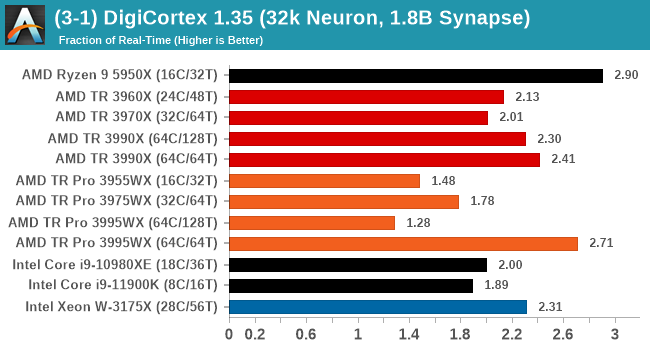
Normally DigiCortex likes memory bandwidth, but most of the TR Pro CPUs wilted in this test. The only mode that did not is the 3995WX in 64C/64T mode, perhaps showcasing this test runs better without SMT enabled.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts

DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
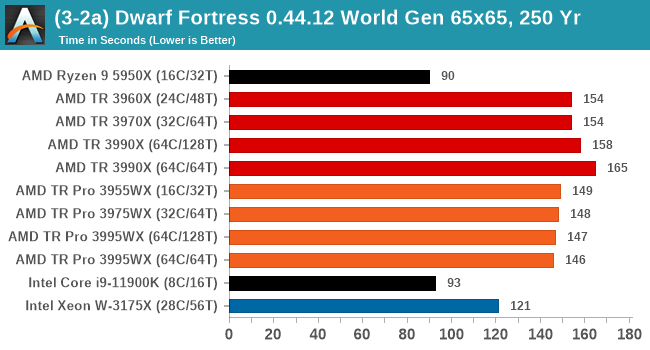
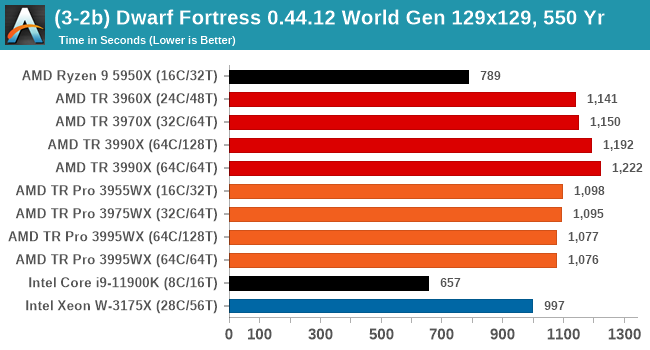
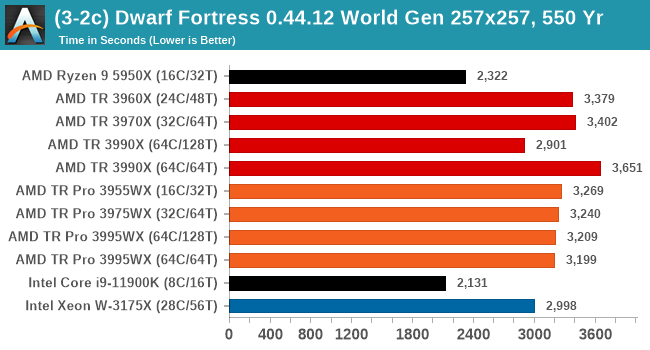
As a mostly ST test, the consumer processors do best here. However overall, TR Pro does better than TR.
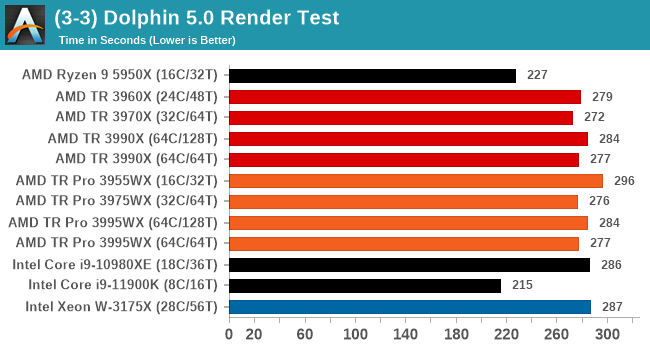
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.
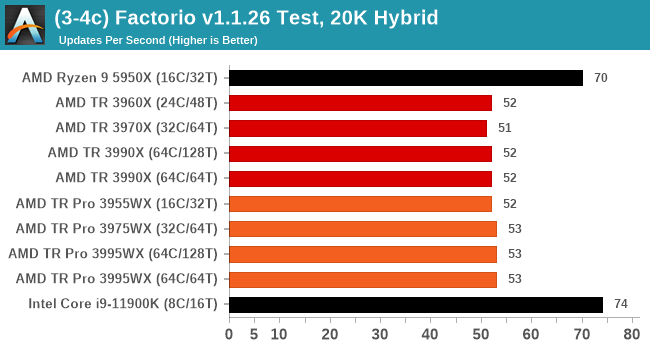
Factorio v1.1.26: Link
One of the most requested simulation game tests we’ve had in recently is that of Factorio, a construction and management title where the user builds endless automated factories of increasing complexity. Factorio falls under the same banner as other simulation games where users can lose hundreds of hours of sleepless nights configuring the minutae of their production line.
Our new benchmark here takes the v1.1.26 version of the game, a fixed map, and uses the automated benchmark mode to calculate how long it takes to run 1000 updates. This is then repeated for 5 minutes, and the best time to complete is used, reported in updates per second. The benchmark is single threaded and said to be reliant on cache size and memory.
Details for the benchmark can be found at this link.










98 Comments
View All Comments
Mikewind Dale - Wednesday, July 14, 2021 - link
I have a ThreadRipper Pro 3955WX, and I discovered something interesting about the memory bandwidth.Originally, I bought 4x64 GB ECC RDIMM because I thought 256 GB might be enough, and I wanted to leave some empty RAM slots to populate with 128 GB RDIMMs if those ever became cost-effective. (Right now, 128 GB RDIMMs are about triple the price of 64 GB.)
CPU-Z and AIDA64 reported "quad" channel memory, and AIDA64's memory benchmarks showed reasonable memory performance.
But I discovered that 256 GB wasn't enough for my application, so I bought 2 more 64 GB RDIMMs.
At this point, I had 6 DIMMs populated. CPU-Z and AIDA64 both reported "hexa" channel memory, but AIDA64's memory benchmarks showed that my memory performance was about 2/3 that of a Ryzen.
So I bought 2 more RDIMMs again, for a total of 8. Now, my memory benchmark in AIDA64 is much closer to expected.
So the moral of the story is: you can populate 4 DIMMs, or you can populate 8, but don't dare populate 6. Populating precisely 6 DIMMs will absolutely cripple your memory performance, whereas 4 DIMMs still have acceptable performance.
kobblestown - Wednesday, July 14, 2021 - link
The 3955 probably has only 2 CCDs and is therefore limited to 4 DDR channels throughput. It seems that each IF link has the throughput of 2 DDR channels and this makes sense.You should keep in mind that the IO die has in effect 4 dual channel controllers and you may have populated them suboptimally. If you have two dual channel controllers fully populated and two half populated (instead of a third fully populated and the fourth one staying empty) you'll have skewed results. Also, there was some noise about Milan working better with 6 channel configurations so it may be something specific to Rome chips.
Rudde - Wednesday, July 14, 2021 - link
Server providers had requested for 6 channel memory support for server processors and that was implemented in Milan.McFig - Wednesday, July 14, 2021 - link
What kobblestown is suggesting is that maybe Mikewind Dale could have gotten the 6 RDIMMs working by moving one of them so that each pair is fully populated.Mikewind Dale - Wednesday, July 14, 2021 - link
McFig, there are only 8 slots, so I'm not sure how I could have moved the 6 DIMMs among the 8 slots to ensure that each pair is populated.1_rick - Wednesday, July 14, 2021 - link
He probably means "each of 3 pairs fully populated".DougMcC - Wednesday, July 14, 2021 - link
I think the question is whether 3/3 is better than 4/2kobblestown - Friday, July 16, 2021 - link
Heya! Sorry for the nebulous formulation. In terms of the number of DIMMS per memory controller, I suggest having 2+2+2+0 instead of 2+1+2+1. One needs to figure out what this means for any particular MB. But as DougMcC suggests, that would probably mean having 4 DIMMs on one side of the CPU and 2 on the other, rather than having 3 DIMMs on each side. The latter is bound to be suboptimal. Whether the former offers an improvement is something that I would be very interested to know but could be that Rome has some shortcoming in this area which is addressed in Milan.Again, dual CCD configurations are limited to 4 channel bandwidth but it's still worth it to have all channels populated so you don't get bitten by badly handled assymetry and the IO does not fight (too much) with the cores for the bandwidth.
kobblestown - Friday, July 16, 2021 - link
BTW, one should also check the memory interleaving options in the UEFI. Maybe the way the IO die aggregates the memory channels can be tweaked to achive the expected performance even with 6 DIMMs. Or maybe that's only achievable with Milan.Mikewind Dale - Friday, July 16, 2021 - link
Ahhh, I see what you mean. Thanks. Well, I have 8 DIMMs now, and I don't want to mess with my system any more. Maybe Anandtech can test this.