Arm Announces Armv9 Architecture: SVE2, Security, and the Next Decade
by Andrei Frumusanu on March 30, 2021 2:00 PM ESTFuture Arm CPU Roadmaps
Not directly related to v9, however tied into the technology roadmap of the upcoming v9 designs in the near future, Arm also talked about some points regarding their projected performance of v9 designs in the next 2 years.
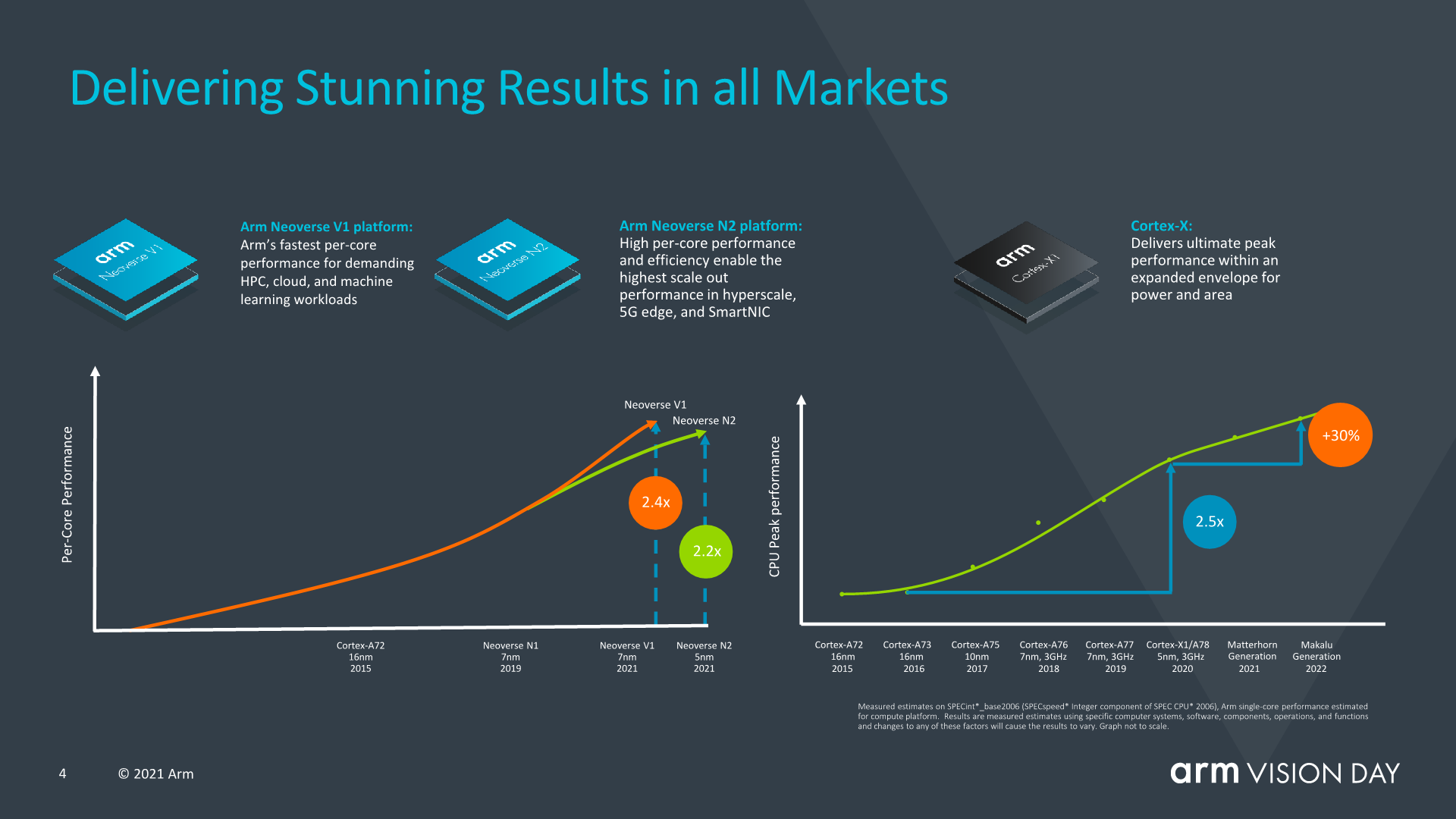
Arm talked about how the mobile space had seen performance increases of 2.4x (we’re talking purely ISO-process design IPC here) of this year’s X1 devices compared to the Cortex-A73 a few years ago in 2016.
Interestingly, Arm also talked about Neoverse V1 designs and how they’re achieving 2.4x the performance of A72 class designs, and discloses that they are expecting the first V1 devices to he released later this year.
For the next-generation mobile IP cores, code-named Matterhorn and Makalu, the company is disclosing an aggregate expected 30% IPC gain across these two generations, excluding frequency or any other additional performance gains which could be reached by SoC designers. This actually represents a 14% generational increases across these two new designs, and as showcased in the performance curve in the slide, would indicate that improvements are slowing down relative to what Arm had managed over the past few years since the A76. Still, the company states that the rate of advancement is still well beyond the industry average – admittedly that is being dragged down by some players.
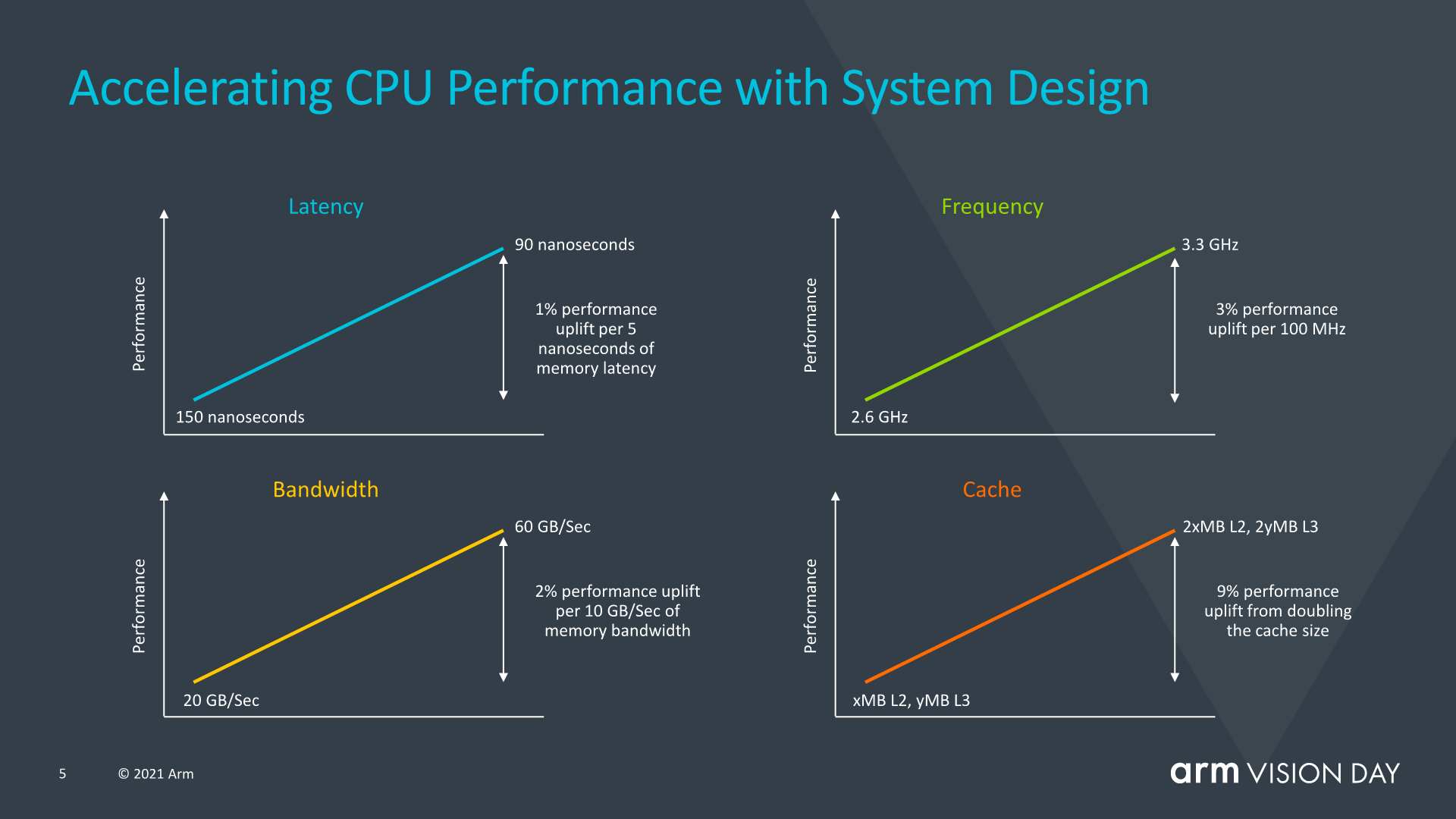
Oddly enough, Arm also included a slide that wanted to focus on the system-side impact on performance, rather than just CPU IP performance. Some of the figures presented here, such as 1% of performance per 5ns of memory latency have been figures that we had talked about extensively for a few generations now, but Arm here also points out that there’s a whole generation of CPU performance that can be squeezed out if one focuses on improving various other aspects of an implementations by improving the memory path, increasing caches, or optimising frequency capabilities. I consider this to be a veiled shot at the current conservative approaches from SoC vendors which are not fully utilising the expected performance headroom of X1 cores, and subsequently also not reaching the expected performance projections of the new core.

Arm continues to see the CPU as the most versatile compute block for the future. While dedicated accelerators or GPUs will have their place, they have a hard time to address important points such as programmability, protection, pervasiveness (essentially ability to run them on any device), and proven abilities to work correctly. Currently, the compute ecosystem is extremely fragmented in how things are run, not only differing between device types, but also differing between device vendors and operating systems.
SVE2 and Matrix multiplication can vastly simplify the software ecosystem, and allow compute workloads to take a step forward with a more unified approach that will be able to run on any device in the future.

Lastly, Arm had a nugget of new information on the future of Mali GPUs, disclosing that the company is working on new technologies such as VRS and in particular Ray Tracing. The latter point is quite surprising to hear, and signals that the desktop and console ecosystem push by AMD’s and Nvidia’s introduction of RT is also expected to push the mobile GPU ecosystem towards RT.
Armv9 designs to be unveiled soon, devices in early 2022
Today’s announcement came in an extremely high-level format, and we expect Arm to talk more about the various details of Armv9 and new features such as CCA in the company’s usual yearly tech disclosures in the coming months.
In general, Armv9 appears to be a mix between a more fundamental ISA shift, which SVE2 can be seen as, and a general re-baselining for the software ecosystem to aggregate the last decade of v8 extensions, and build the foundation for the next decade of the Arm architecture.
Arm had already talked about the Neoverse V1 and N2 late last year, and I do expect the N2 at least to be eventually unveiled as a v9 design. Arm further discloses to expect more Armv9 CPU designs, likely the mobile-side Cortex-A78 and X1 successors, to be unveiled this year, with the new CPUs likely to have already been taped-in by the usual SoC vendors, and expected to be seen in commercial devices in early 2022.








74 Comments
View All Comments
SarahKerrigan - Tuesday, March 30, 2021 - link
Good to see SVE2 in base, though some of the choices being made by software projects around how to implement SVE have seemed a bit grody.CCA looks like TZ-rooted virtualization.
skavi - Tuesday, March 30, 2021 - link
Substantially more grody than typical SIMD? Any open source examples?SarahKerrigan - Tuesday, March 30, 2021 - link
Last time I looked at Eigen, IIRC, it was requiring a width to be specialized at compile-time... which kind of defeats the purpose. I only glanced over it briefly, so maybe I misunderstood.emn13 - Saturday, April 3, 2021 - link
It wouldn't surprise me that a compile-time specialized width is more efficient; part of eigen's extremely low overhead is that most of the decisions can be made compile time, and are often at least partially amenable to inlining, which in turn enables better compiler optimizations in general.Additionally, while it sounds great on paper that your vector size is flexible, I'm skeptical that the hardware will run as efficiently at it's true native sizes, as it would at larger sizes. It's quite possibly more efficient to target the true vector size for whatever operation you're running and in software schedule the iteration, because sometimes the algorithms involved are amenable to interleaving with other operations and/or other (more efficient) orderings. It's pretty difficult for the hardware to just guess what you're doing - in principle at least. But maybe ARM pulled it off; I'm just speculating here.
Finally, eigen is a pretty old project by now, with lots of in-depth optimizations for a whole bunch of algorithms and architectures. It's possible the code-base simply made common assumptions (namely fixed-size vectors) in so many places it's hard to change (though if "huge" sizes like 2048b had no additional overhead, why wouldn't eigen just target that?)
TL;DR: it might be a software design limitation, but it strikes me as at least as plausible that the flexible vector sizes still aren't as efficient as using the true vector size.
katiko - Thursday, April 1, 2021 - link
niceKangal - Thursday, April 1, 2021 - link
I know, I know, bu it has to be said though........what are the implications of ARM v9 in terms of other nations and companies?
In particularly, People's Republic of China, with their strong-arming of other companies and nations by using economic sanctions and mass media manipulation to get their way? This "trade war" has allowed us a glimpse of the ugly side of both super-powers. And things looks very questionable when probing into their nationalised-companies like Huawei and SMIC (in contrast to Cisco and Intel).
Will this (ARM v9) pave a way forward where China essentially misses out? Sort of like being forced to use a Snapdragon 805 (or Android 4.4), when your competitors are using the Snapdragon 820 (or Android 5.1). Key point in that analogy is the 64-bit support. Is that scenario good thing? Would that lead to China allowing for a proper unfiltered Internet? Or perhaps to China allowing foreign companies to their internal market? Does it matter? Or would it lead to nothing, except simply reduced competition in China and Global Markets?
vladx - Thursday, April 1, 2021 - link
Not gonna happen, ARM just recently announced it will continue to provide new SoC designs to Huawei.dotjaz - Friday, April 2, 2021 - link
What drugs are you on? Why would ARM get involved in this political mess? And why would ARM be able to force anything? You do realise cutting China off can only result in one thing, they euther abandon armv9 completely and turn to RISC-V or simply implement armv9 without a license, what you gonna do? Revoke their license?dotjaz - Friday, April 2, 2021 - link
In any case their strategy would be leaving ARM Ltd. behind, like they did with MIPS initially.Kangal - Saturday, April 3, 2021 - link
I doubt China would abandon crucial technology. I think they would rather seek out corruption in Companies and Governments, and gain access to the technology through alternative means. Or even more likely, they'd levarage their own infrastructure (or economy) as a tit-for-tat bargaining and gain official access through that way. Especially when knowing the short-sightedness of many politicians.