The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTTuring RT Cores: Hybrid Rendering and Real Time Raytracing
As it presents itself in Turing, real-time raytracing doesn’t completely replace traditional rasterization-based rendering, instead existing as part of Turing’s ‘hybrid rendering’ model. In other words, rasterization is used for most rendering, while ray-tracing techniques are used for select graphical effects. Meanwhile, the ‘real-time’ performance is generally achieved with a very small amount of rays (e.g. 1 or 2) per pixel, and a very large amount of denoising.
The specific implementation is ultimately in the hands of developers, and NVIDIA naturally has their raytracing development ecosystem, which we’ll go over in a later section. But because of the computational intensity, it simply isn’t possible to use real-time raytracing for the complete rendering workload. And higher resolutions, more complex scenes, and numerous graphical effects also compound the difficulty. So for performance reasons, developers will be utilizing raytracing in a deliberate and targeted manner for specific effects, such as global illumination, ambient occlusion, realistic shadows, reflections, and refractions. Likewise, raytracing may be limited to specific objects in a scene, and rasterization and z-buffering may replace primary ray casting while only secondary rays are raytraced. Thus, the goal of developers is to use raytracing for the most noticeable and realistic effects that rasterization cannot accomplish.
Essentially, this style of ‘hybrid rendering’ is a lot less raytracing than one might imagine from the marketing material. Perhaps a blunt way to generalize might be: real time raytracing in Turing typically means only certain objects are being rendered with certain raytraced graphical effects, using a minimal amount of rays per pixel and/or only raytracing secondary rays, and using a lot of denoising filtering; anything more would affect performance too much. Interestingly, explaining all the caveats this way both undersells and oversells the technology, because therein lies the paradox. Even in this very circumscribed way, GPU performance is significantly affected, but image quality is enhanced with a realism that cannot be provided by a higher resolution or better anti-aliasing. Except ‘real time’ interactivity in gaming essentially means a minimum of 30 to 45 fps, and lowering the render resolution to achieve those framerates hurts image quality. What complicates this is that real time raytracing is indeed considered the ‘holy grail’ of computer graphics, and so managing the feat at all is a big deal, but there are equally valid professional and consumer perspectives on how that translates into a compelling product.
On that note, then, NVIDIA accomplished what the industry was not expecting to be possible for at least a few more years, and certainly not at this scale and development ecosystem. Real time raytracing is the culmination of a decade or so of work, and the Turing RT Cores are the lynchpin. But in building up to it, NVIDIA summarizes the achievement as a result of:
- Hybrid rendering pipeline
- Efficient denoising algorithms
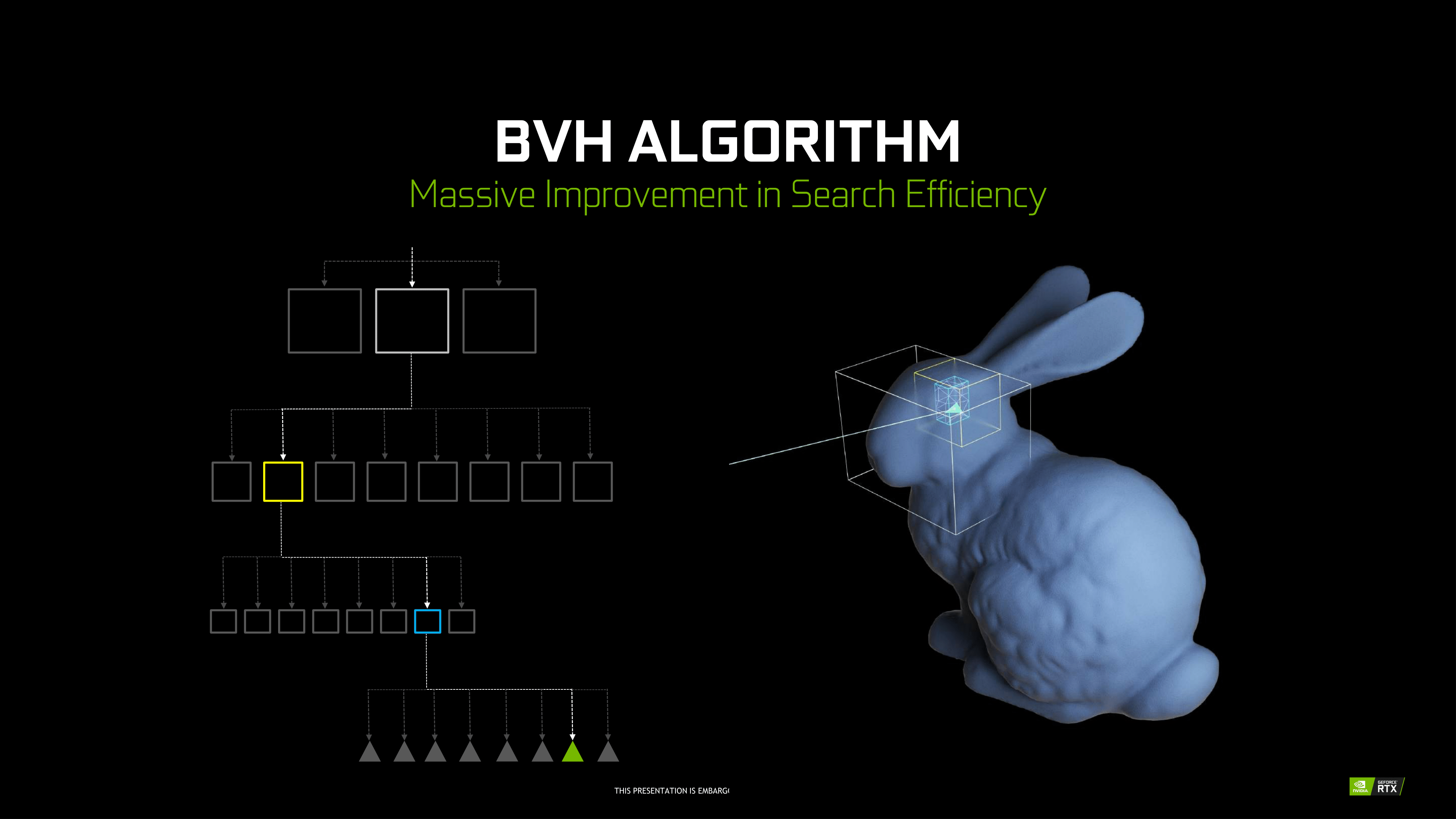
- Efficient BVH algorithms
By themselves, these developments were unable to improve raytracing efficiency, but set the stage for RT Cores. By virtue of raytracing’s importance in the world of computer graphics, NVIDIA Research has been looking into various BVH implementations for quite some time, as well as exploring architectural concerns for raytracing acceleration, something easily noted from their patents and publications. Likewise with denoising, though the latest trend has veered towards using AI and by extension Tensor Cores. When BVH became a standard of sorts, NVIDIA was able to design a corresponding fixed function hardware accelerator.
Being so crucial to their achievement, NVIDIA is not disclosing many details about the RT Cores or their BVH implementation. Of the details given, much is somewhat generic. To reiterate, BVH is a rather general category, and all modern raytracing acceleration structures are typically BVH or kd-tree based.
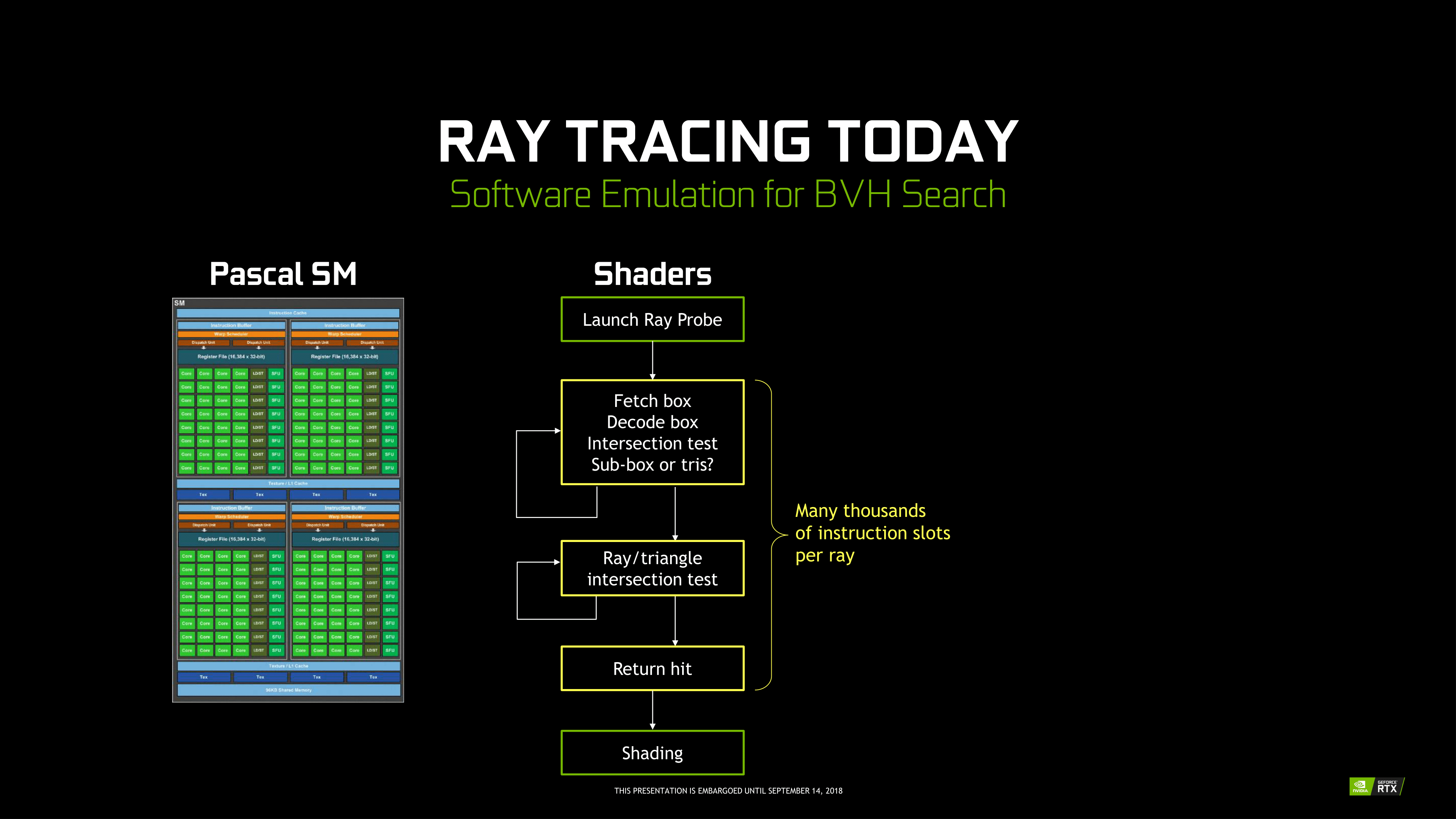
Unlike Tensor Cores, which are better seen as an FMA array alongside the FP and INT cores, the RT Cores are more like a classic offloading IP block. Treated very similar to texture units by the sub-cores, instructions bound for RT Cores are routed out of sub-cores, which is later notified on completion. Upon receiving a ray probe from the SM, the RT Core proceeds to autonomously traverse the BVH and perform ray-intersection tests. This type of ‘traversal and intersection’ fixed function raytracing accelerator is a well-known concept and has had quite a few implementations over the years, as traversal and intersection testing are two of the most computationally intensive tasks involved. In comparison, traversing the BVH in shaders would require thousands of instruction slots per ray cast, all for testing against bounding box intersections in the BVH.
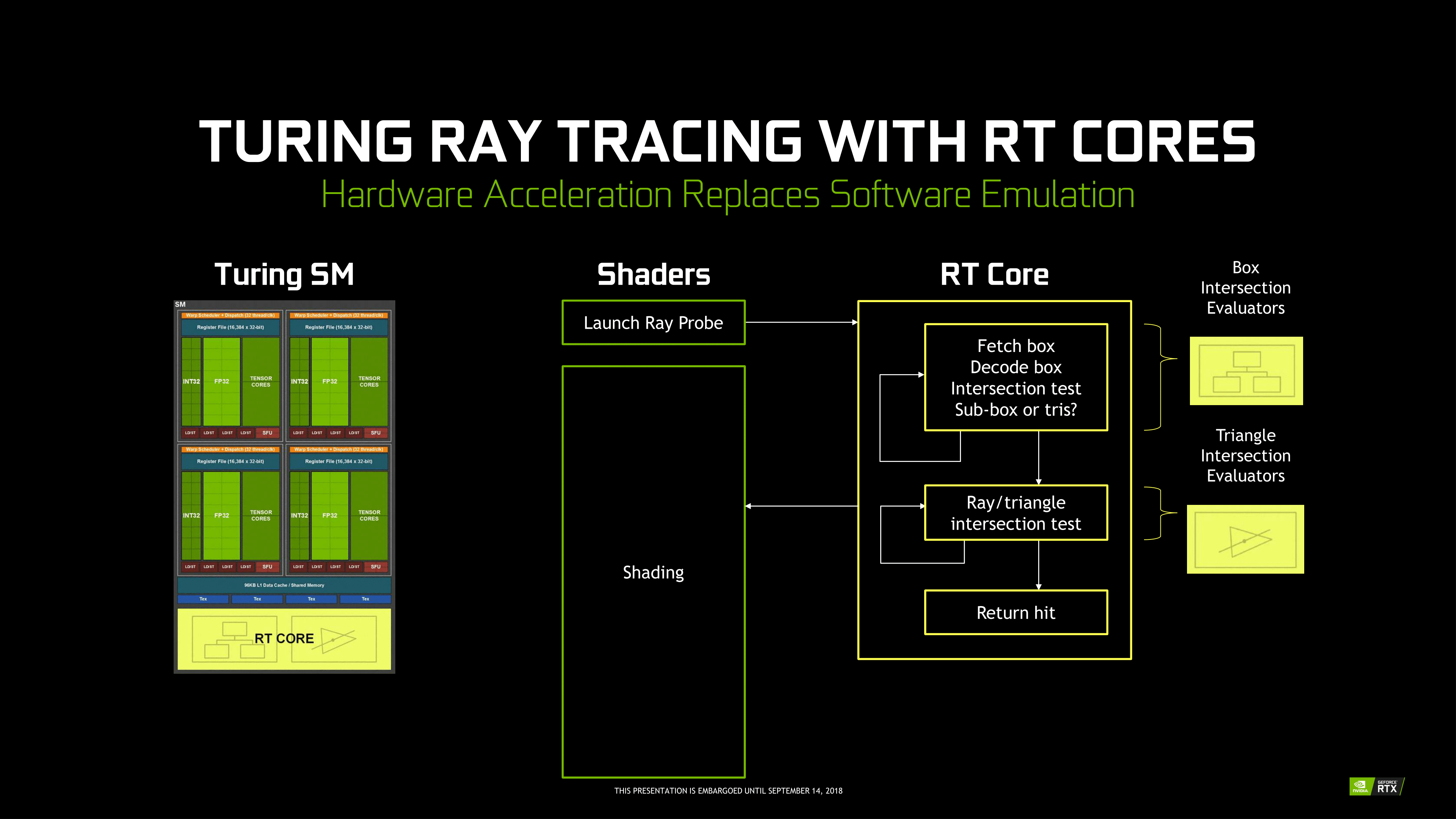
Returning to the RT Core, it will then return any hits and letting shaders do implement the result. The RT Core also handles some grouping and scheduling of memory operations for maximizing memory throughput across multiple rays. And given the workload, presumably some amount of memory and/or ray buffer within the SIP block as well. Like in many other workloads, memory bandwidth is a common bottleneck in raytracing, and has been the focus of several NVIDIA Research papers. And in general, raytracing workloads result in very irregular and random memory accesses, mainly due to incoherent rays, that prove especially problematic for how GPUs typically utilize their memory.
But otherwise, everything else is at a high level governed by the API (i.e. DXR) and the application; construction and update of the BVH is done on CUDA cores, governed by the particular IHV – in this case, NVIDIA – in their DXR implementation.
All-in-all, there’s clearly more involved, and we’ll be looking to run some microbenchmarks in the future. NVIDIA’s custom BVH algorithms are clearly in play, but right now we can’t say what the optimizations might be, such as compressions, wide BVH, node subdivision into treelets. The way the RT Cores are integrated into the SM and into the architecture is likely crucial to how it operates well. Internally, the RT Core might just be a basic traversal and intersection unit, but it might also have other bits inside; one of NVIDIA’s recent patents provide a representation, albeit dated, of what else might be present. I, for one, would not be surprised to see it closely tied with the MIO blocks, and perhaps did more with coherency gathering by manipulating memory traffic for higher efficiency. It would need to coordinate well with the other workloads in the SMs without strangling memory access with unmitigated incoherent rays.
Nevertheless, details like performance impact are as yet unspecified.








111 Comments
View All Comments
xXx][Zenith - Friday, September 14, 2018 - link
Nice write-up! With 25% of the chip area dedicated to Tensor Cores and other 25% to RT Cores NVIDIA is betting big on DLSS and RTX for gaming usecases. With all the architectural improvements, better memory compression ... AMD is out of the game, quite frankly.Btw, for the fans of GigaRays/Sec, aka CEO metric, here is a Optix-RTX benchmark for Volta, Pascal and Maxwell GPUs: https://www.youtube.com/watch?v=ULtXYzjGogg
OptiX 5.1 API will work with Turing GPUs but will not take advantage of the new RT Cores, so older-gen NV GPUs can be directly compared to Turing. Application devs need to rebuild with Optix 5.2 to get access to HW accelarated ray tracing. Imho, RTX cards will have nice speedup with Turing RT Cores using GPU renderers (Octane, VRay, ...) but the available RAM will limit the scene complexity big time.
blode - Friday, September 14, 2018 - link
hate when i lose a game before my opponent arriveseddman - Friday, September 14, 2018 - link
As far as I can tell, GigaRays/Sec is not an nvidia made term. It's been used before by others too, like imagination tech.The nvidia made up term is RTX-ops.
xXx][Zenith - Friday, September 14, 2018 - link
Ray tracing metric without scene complexity, viewport placement is just smoke and mirrors ...From whitepaper: "Turing ray tracing performance with RT Cores is significantly faster than ray tracing in Pascal GPUs. Turing can deliver far more Giga Rays/Sec than Pascal on different workloads, as shown in Figure 19. Pascal is spending approximately 1.1 Giga Rays/Sec, or 10 TFLOPS / Giga Ray to do ray tracing in software, whereas Turing can do 10+ Giga Rays/Sec using RT Cores, and run ray tracing 10 times faster."
eddman - Saturday, September 15, 2018 - link
I don't know the technical details of ray tracing, but how is that nvidia statement related to scene complexity, etc?From my understanding of that statement, they are simply saying that turing is able to deliver far more rays/sec than pascal, because it is basically hardware-accelerating the operations through RT cores but pascal has to do all those operations in software through regular shader cores.
niva - Wednesday, September 19, 2018 - link
If you hold scene complexity constant (take the same environment/angle) and run a ray tracing experiment, the new hardware will be that much faster at cranking out frames. At least that's how I'm interpreting the article and the statement above, I'm not really sure if that's accurate though...Yojimbo - Saturday, September 15, 2018 - link
When did Imgtec use gigarays? As far as I remember they didn't have hardware capable of a gigaray. They measured in hundreds of millions of rays per second, and I don't remember them using the term "megaray", either. Just something along the lines of "200 million rays/sec".eddman - Saturday, September 15, 2018 - link
Why fixate on the "giga" part? I obviously meant rays/sec; forgot top remove the giga part after copy/paste. A measuring method doesn't change with quantity.Yojimbo - Saturday, September 15, 2018 - link
Because the prefix is the whole point. The point is the terminology, not the measuring method. Rays per second is pretty obvious and has probably been around since the 70s. The "CEO metric" the OP was talking about was specifically about "gigarays per second". Jensen Huang said it during his SIGGRAPH presentation. Something like "Here's something you probably haven't heard before. Gigarays. We have gigarays."eddman - Saturday, September 15, 2018 - link
What are you on about? He meant "giga" as in "billion". It's so simple. He said it that way to make it sound impressive.